Summary
Proteins designed de novo from language models interpolate the design space of their training data, mirroring how naturally occurring proteins also borrow heavily form each other. Brian Naughton in a series of twitter posts noted that esmGFP (generated using (ESM)3) has 58% sequence identity to any naturally occurring GFP, but 74% when considering mixing and matching across protein sequences (https://gistpreview.github.io/?81c106aa6e8519bcc77acdbde939a2fa/ESM3_GFP_alignment.html). Likewise, the CRISPR enzyme openCRISPR (generated using fine-tuned (ProGen2)) from (1) can be recreated to 98% completion using three Streptococcus sequences (https://gistpreview.github.io/?f6684bb2fefa838bfff5082465df2ff0).
Figures
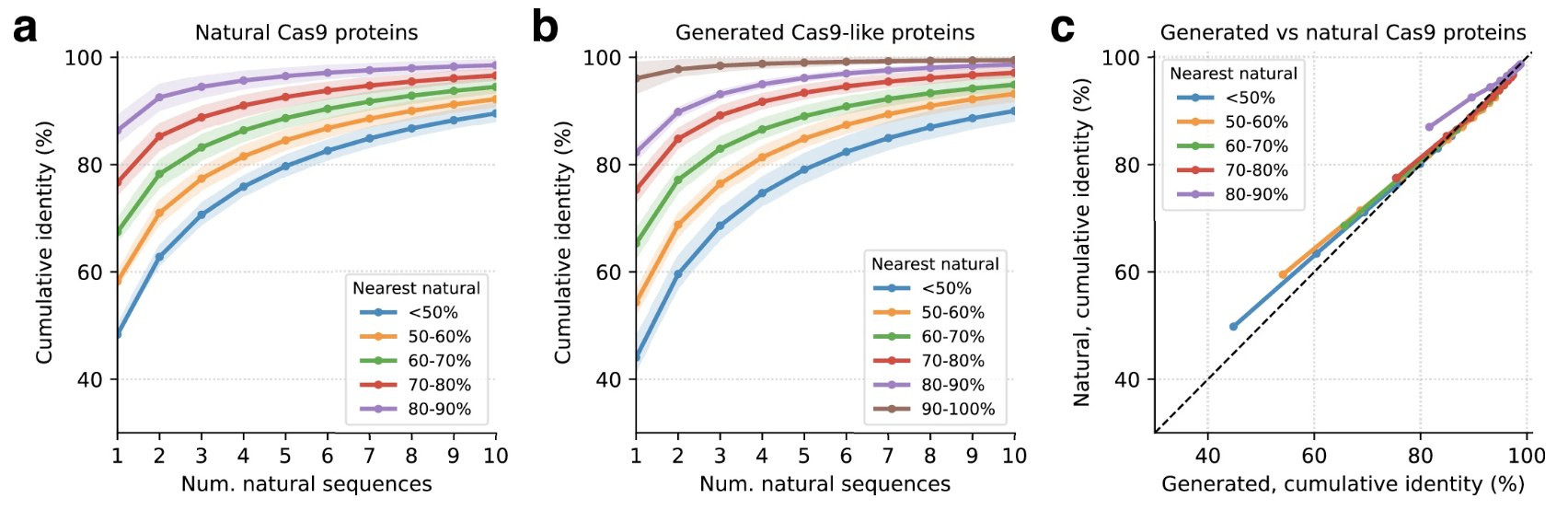 Ref (1)
Ref (1)
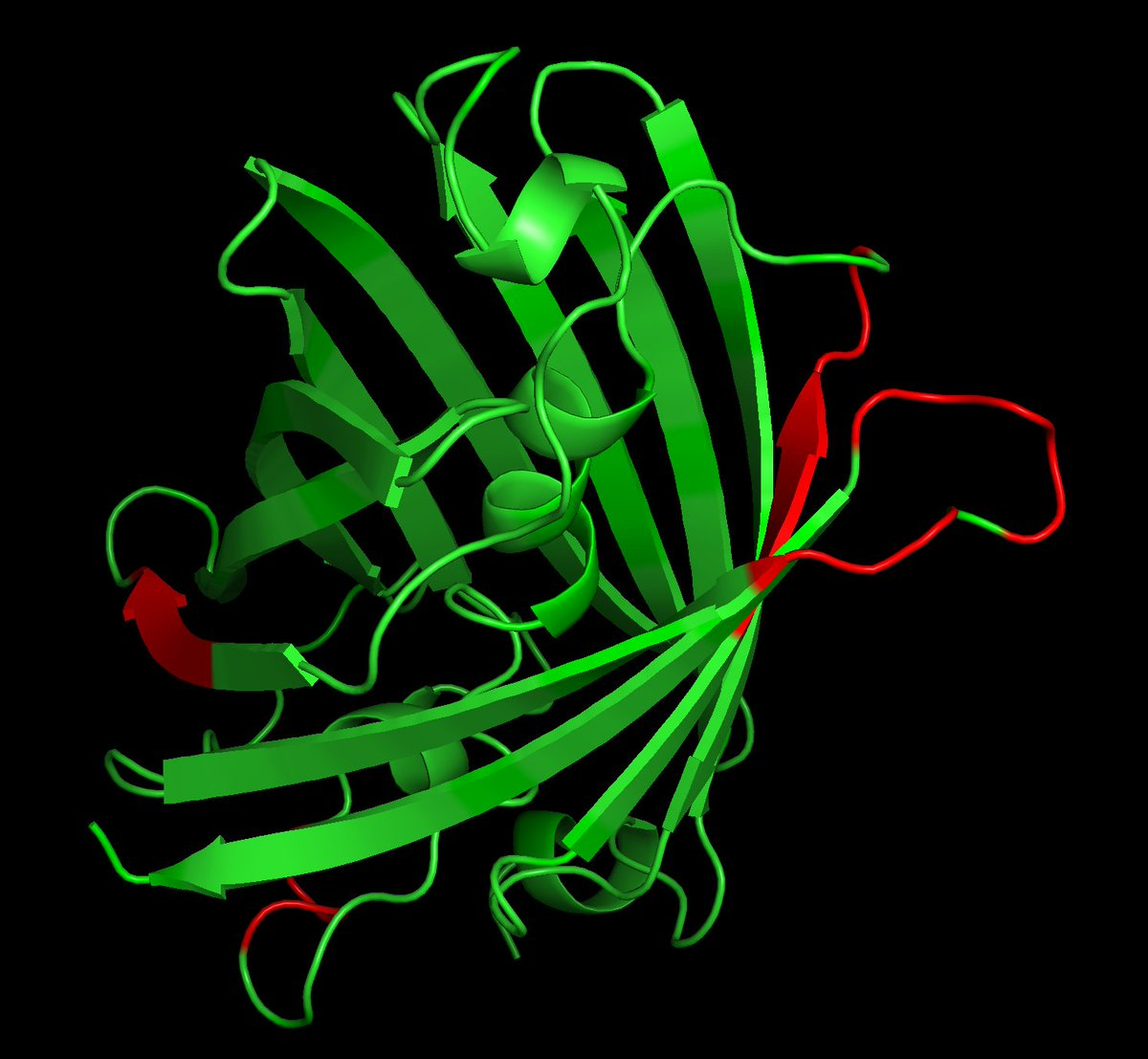 Ref Brian Naughton’s Twitter; red regions have two or more consecutive novel residues; the long loop in the top right is not conserved
Ref Brian Naughton’s Twitter; red regions have two or more consecutive novel residues; the long loop in the top right is not conserved