Summary
** (1) use a specialized form of Disentangled attention when training the structure model DeProt.** The main difference is that they include structure in addition to info about sequence-derived representations and position. As with the NLP-derived disentangled attention which ignores position-position attention matrices, they also ignore structure-position, position-structure, structure-structure, and position-position.
Details
Structure-based embeddings were derived using GVP and quantized into one of several thousand categories. The number strongly affected performance of zero-shot stability prediction.
Figures
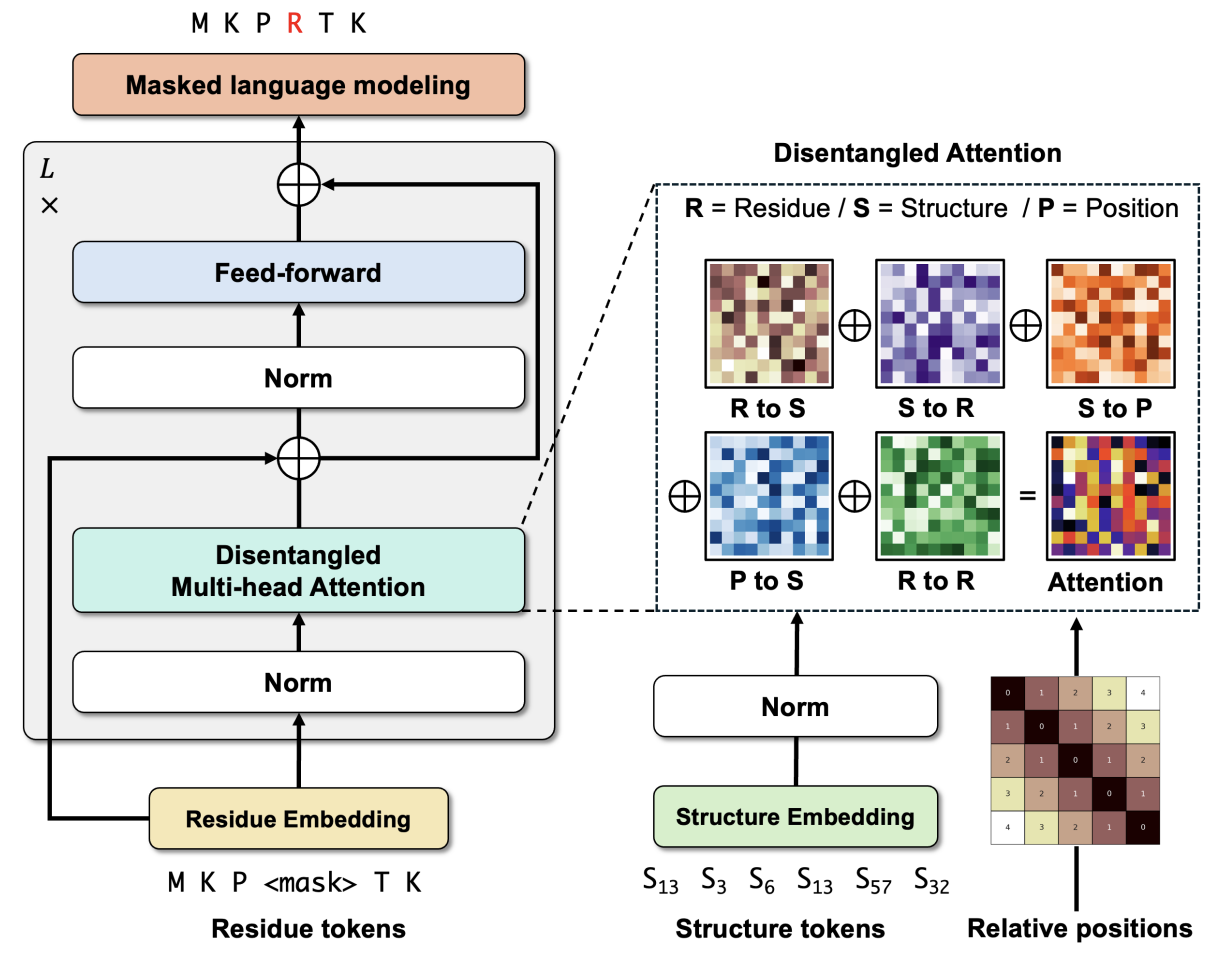
Figure 1 from (1)
1.
Li M, Tan P, Ma X, Zhong B, Yu H, Zhou Z, et al. ProSST: Protein Language Modeling with Quantized Structure and Disentangled Attention. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.04.15.589672