Summary
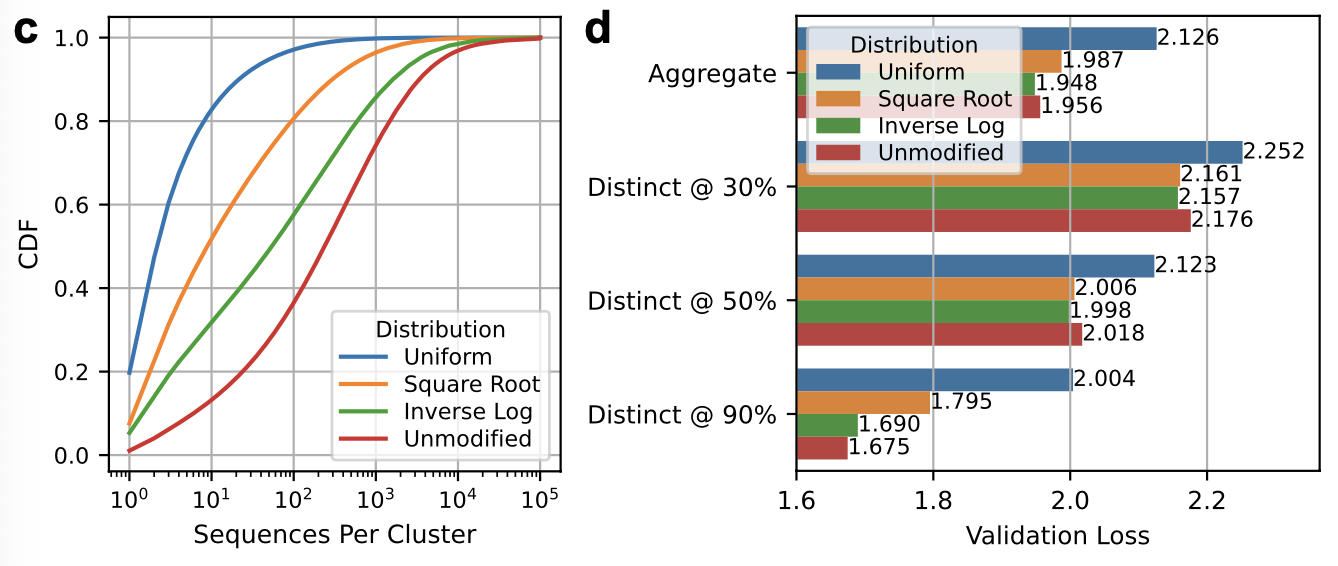
Alternate sequence clustering schemes outperform uniform sampling when training protein language models (1). Uniform sampling, which is standard in the field, performed worse than sampling strategies that account for the increased presence of some protein families, and even worse than simply sampling all sequences (after 90% clustering). This suggests that sequence propensity may encode some useful information.
Figures
 Ref (1)
Ref (1)
See also
1.
Bhatnagar A, Jain S, Beazer J, Curran SC, Hoffnagle AM, Ching KS, et al. Scaling Unlocks Broader Generation and Deeper Functional Understanding of Proteins. openRxiv; 2025. Available from: https://doi.org/10.1101/2025.04.15.649055