Protein language models (PLMs) are a type of Transformer model trained on either protein sequences or Multiple sequence alignments.
Methods
Single-sequence
- ESM: currently the most widely-used encoder PLM
- ProGen: probably the most widely-used decoder PLM
- ProtBERT and DistillProtBERT (1)
- ProteinNPT
- xTrimoPGLM
- CARP: A CNN that performs as well as transformer-based methods on both pretraining and downstream tasks. Anecdotally, these can’t indirectly calculate contact maps via the Categorical Jacobian method as well as transformer-based models.
- DASM (deep amino acid sequence model), which is trained on germline-descendant point mutation pairs to learn relative mutation frequencies, after normalizing for expected mutation frequencies in the codon table (2).
Notes
General observations
- PLMs are in-context learners that default to retrieving information from nearby repeats (3).
Representations
- Multiple instance learning using PLM embeddings of all genes in a viral genome identifies which sequences are responsible for host tropism (4). For example, this ranked the Spike protein as the key contributor of host tropism.
- Homolog detection using PLM representations can be improved by compression (5). Using the full representations worsened detection AUC by 7.4%.
- PLMs with a smoother representation space are better predictors of protein function (6).
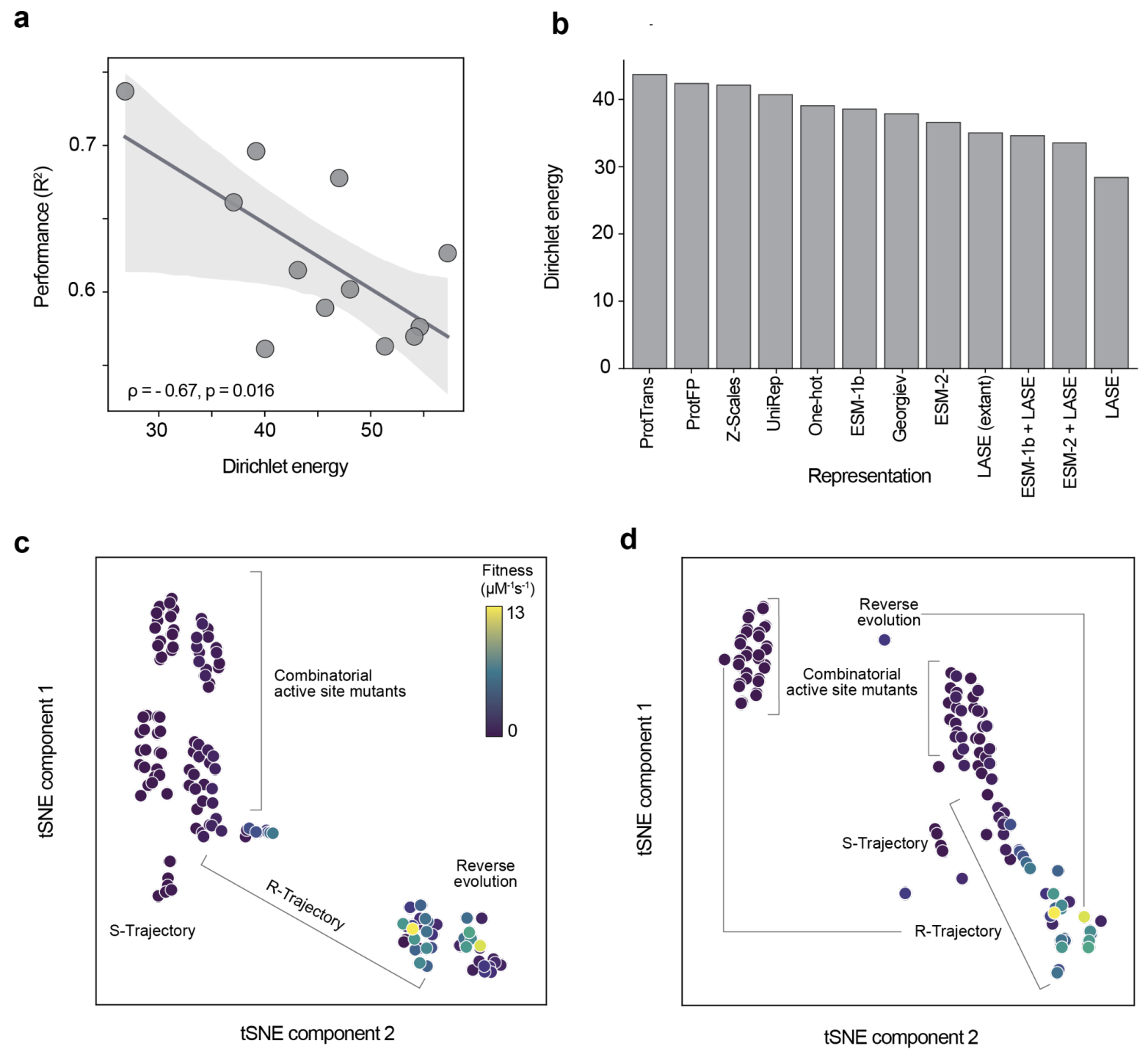 Figure from (6)
Figure from (6)
Hybrid PLM-inverse folding models
From Hybrid sequence-structure models
Training
- Matthews et al. (6) found that masking 0.5% of residues when training PLMs improved predictive performance (greater ) relative to 15% used by ESM.
1.
Geffen Y, Ofran Y, Unger R. DistilProtBert: a distilled protein language model used to distinguish between real proteins and their randomly shuffled counterparts. Bioinformatics. 2022;38(Supplement_2):ii95–8. Available from: https://doi.org/10.1093/bioinformatics/btac474
2.
Bitbol A-F. eLife Assessment: Separating selection from mutation in antibody language models. 2026; Available from: https://doi.org/10.7554/elife.109644.3.sa0
3.
Kantroo P, Wagner GP, Machta BB. In-Context Learning can distort the relationship between sequence likelihoods and biological fitness. 2025; Available from: https://arxiv.org/abs/2504.17068
4.
Liu D, Young F, Lamb KD, Robertson DL, Yuan K. Prediction of virus-host associations using protein language models and multiple instance learning. PLOS Computational Biology. 2024;20(11):e1012597. Available from: https://doi.org/10.1371/journal.pcbi.1012597
5.
Kilinc M, Jia K, Jernigan RL. Improved global protein homolog detection with major gains in function identification. Proceedings of the National Academy of Sciences. 2023;120(9). Available from: https://doi.org/10.1073/pnas.2211823120
6.
Matthews DS, Spence MA, Mater AC, Nichols J, Pulsford SB, Sandhu M, et al. Leveraging ancestral sequence reconstruction for protein representation learning. Nature Machine Intelligence. 2024;6(12):1542–55. Available from: https://doi.org/10.1038/s42256-024-00935-2