Summary
Layer normalization is a procedure to normalize the values of each token to a gaussian with mean and width : where and are the per-token mean and standard deviations, respectively. In the original Transformer paper (1), the Post-LN approach was used where layer normalization followed multi-head attention and again after the feed-forward network, but more recent methods (as of June 2024) use the Pre-LN approach where layer normalization precedes attention and the feed-forward network (2).
Figures
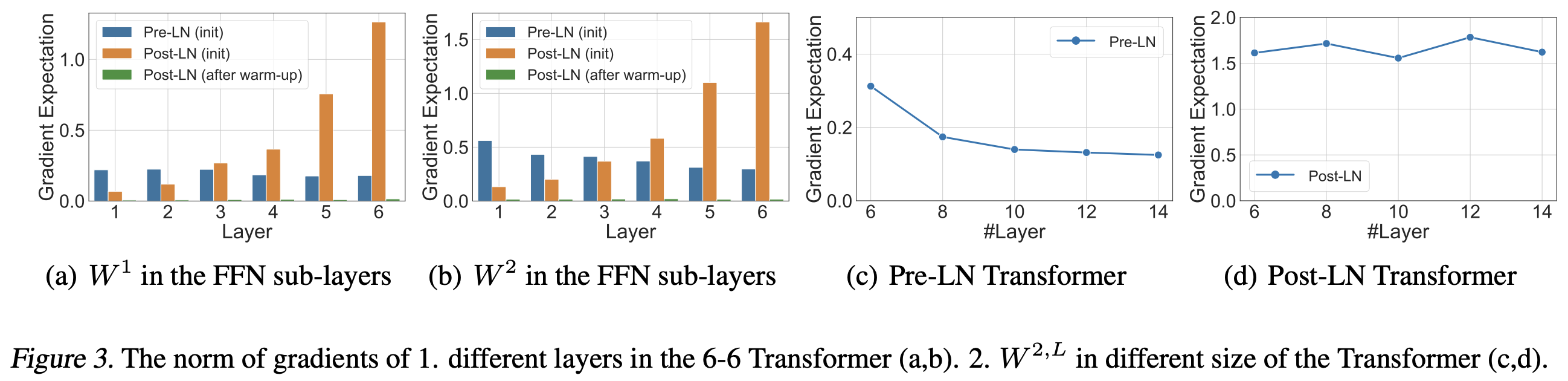 Ref (2)
Ref (2)
1.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention Is All You Need. 2017; Available from: https://arxiv.org/abs/1706.03762
2.
Xiong R, Yang Y, He D, Zheng K, Zheng S, Xing C, et al. On Layer Normalization in the Transformer Architecture. In: International Conference on Machine Learning. PMLR; 2020. p. 10524–33. Available from: https://proceedings.mlr.press/v119/xiong20b.html