Summary
When training neural networks, learning rate decay is used to gradually lower the learning rate over a fixed training duration. Typically cosine decay is used, though this has the disadvantage of being carried out over a predefined duration that cannot easily be extended. (1) found that Weight averaging can work in tandem with this but cannot replace it.
Figures
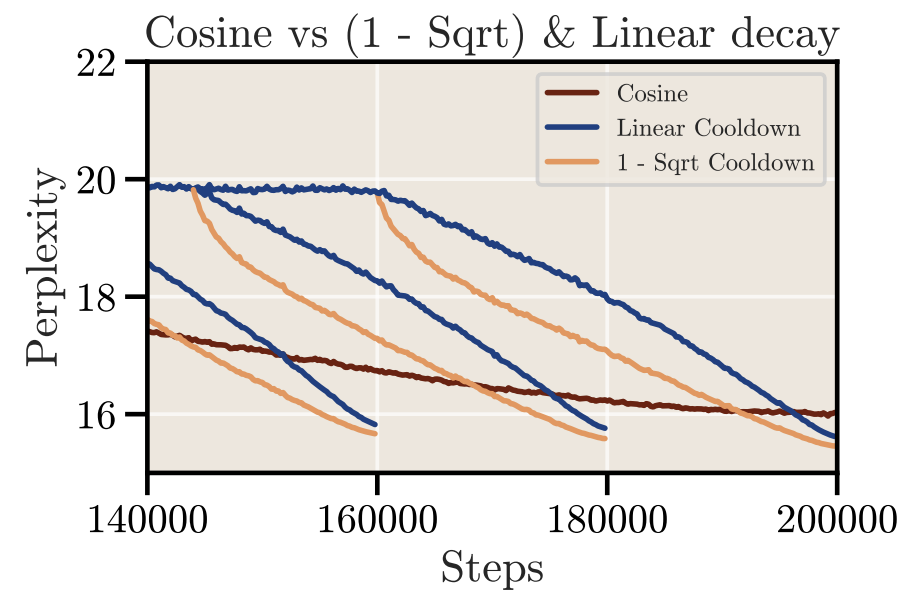 Ref (1)
Ref (1)
Types
- Cosine decay
- Linear decay (or “trapezoidal” decay)
- Square root decay: , with 5% of training steps dedicated to cooldown (1)
- Schedule-free optimization
1.
Allal L, Bakouch E, Hägele A, Jaggi M, Kosson A, Von Werra L. Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations. In: Advances in Neural Information Processing Systems 37. Neural Information Processing Systems Foundation, Inc. (NeurIPS); 2024. p. 76232–64. Available from: https://doi.org/10.52202/079017-2427