The mixture-of-depths method enforces a fixed-size compute budget for variable-length inputs to individual layers of a Transformer (1). In other words, only the top tokens will be used for multi-head attention. Raposo et al. (1) also combined this with Mixture-of-experts.
Figures
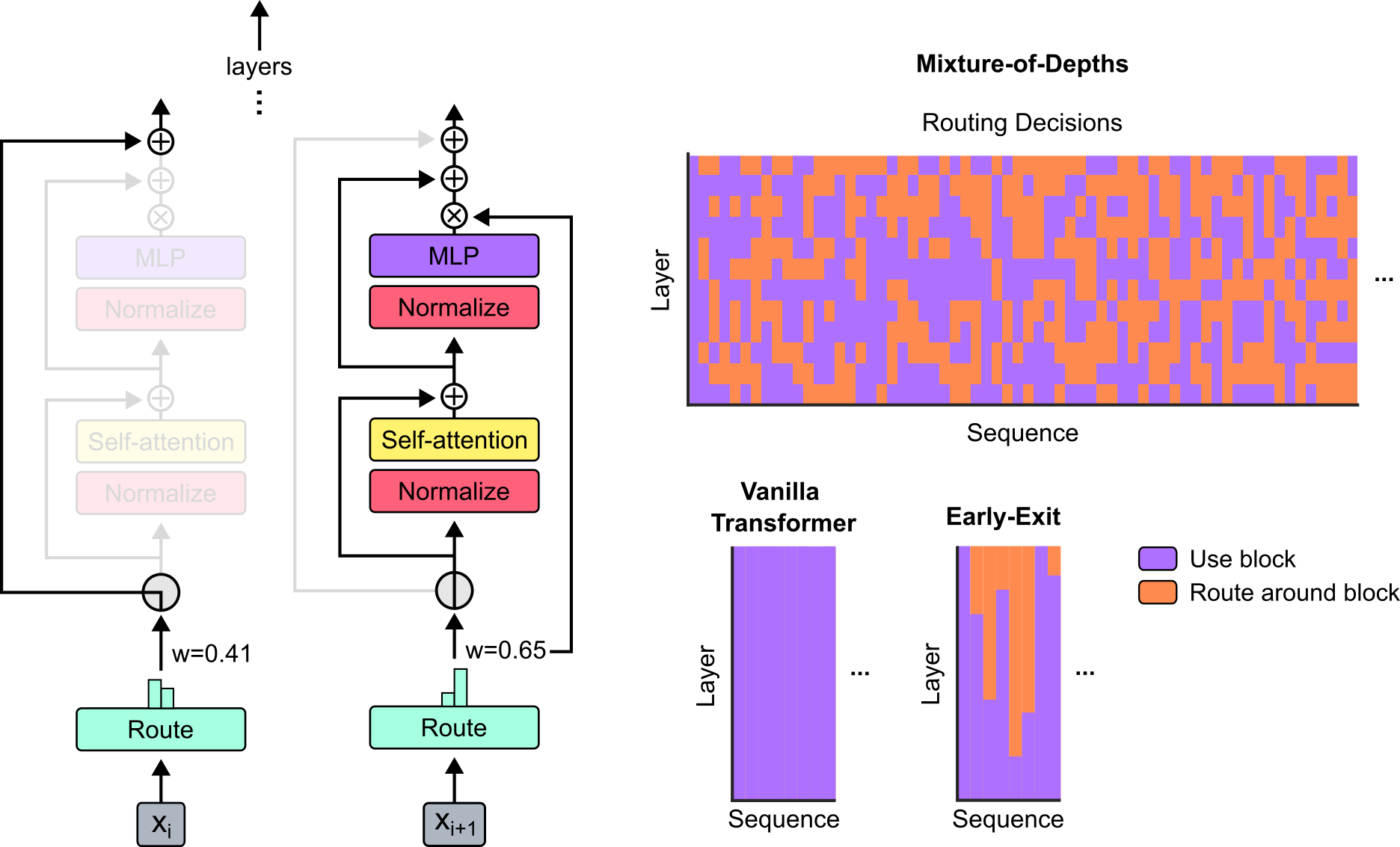 Ref (1)
Ref (1)
1.
Raposo D, Ritter S, Richards B, Lillicrap T, Humphreys PC, Santoro A. Mixture-of-Depths: Dynamically allocating compute in transformer-based language models. 2024; Available from: https://arxiv.org/abs/2404.02258