Mixture of experts is a machine learning method used especially in Transformer models that allows multiple small models with distinct specializations to work in tandem. There is a rumor that GPT-4 is a mixture-of-experts model. They outperform equivalently sized dense models on fixed compute budgets.
Details
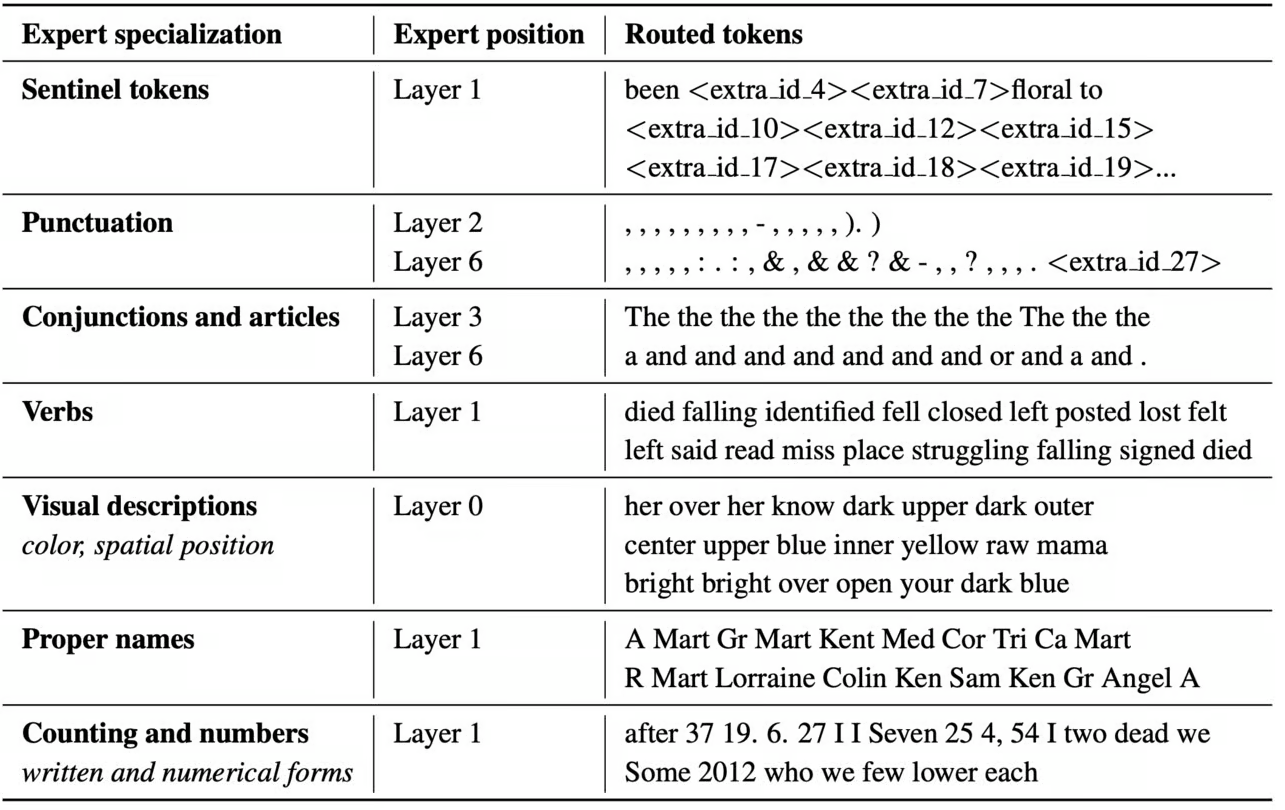
Experts are chosen via top- method, top- method, hash routing, BASE routing, Reinforcement learning, or expert choice routing. Hyperparameters include the number of expert models, size of each expert model, and number of layers of expert models. In GLaM (64 experts per MoE layer, 64B params each), only 8% of parameters activate on average per query. A challenge with this approach is the uneven batch sizing as different samples from the same batch go through different experts.
 From
From