Model merging refers to the process of combining the weights of two or more neural networks with identical architectures to improve robustness.
Approaches
Borrows extensively from Goddard et al. (1)
Linear interpolation/model soup: Multiple models generated on the same data (with the same split) with different hyperparameters. Uniform soup refers to averaging without weighting, while greedy soup refers to averaging each model one at a time but only keeping the change if accuracy is improved. However, it has been shown to lead to catastrophic decreases in model accuracy if interpolation is carried out between models that don’t share an optimization trajectory (2).
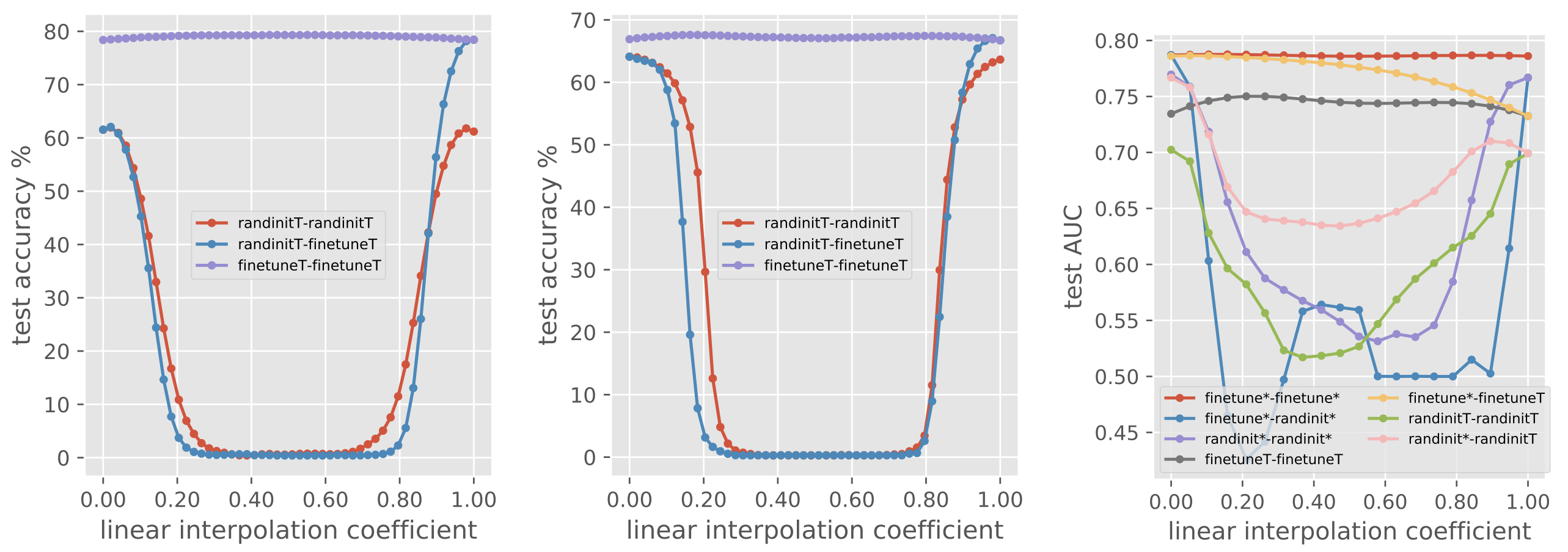 Ref (2)
Ref (2)
Task arithmetic: Adds and/or subtracts model weights derived from neural networks fine-tuned for discrete tasks.
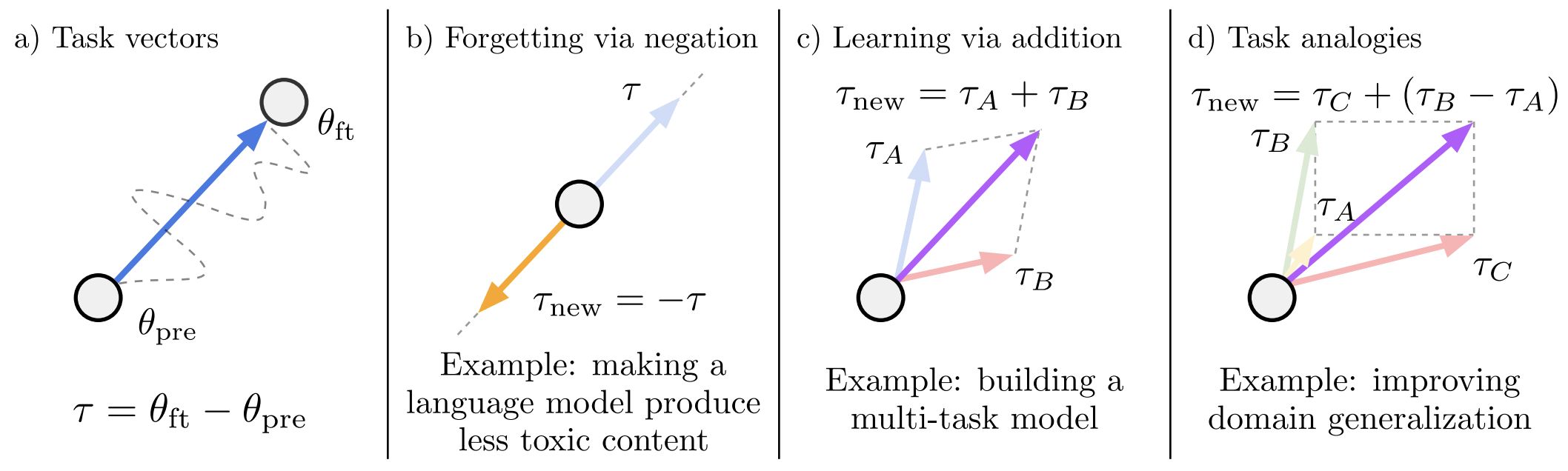 Ref (3)
Ref (3)
Trim, elect sign, merge: Also merges task-specific fine-tuned models (4). Proceeds in three steps: (1) Trim — only the influential parameter values are retained by setting redundant values in each task vector to zero; (2) Elect sign — remove sign conflicts; (3) Merge — merge parameters with consistent sign changes by taking the mean. This approach was found to outperform other approaches for both executing finetuning tasks and out-of-distribution generalization. Task arithmetic was a close second. On soup-like tasks that merge multiple models trained on the same objective, it matches or outperforms all other options, including ensembling. It also works well to generate starting points for initialization.
Fisher merging calculates importance of each parameter for a task by approximating the Fisher Information Matrix. Spherical linear interpolation (SLERP) interpolates between the weight values of two trained neural networks. Model ratatouille allows reuse of multiple fine-tuned models (derived from the same base model). DARE drops certain parameters at a pre-specified rate () and scales the remainder at an inverse rate (). RegMean computes a model with closest similarity to activations of the two models of interest. LoraHub uses black-box optimization to merge two or more LoRA matrices (5); however this falls short of full LoRA fine-tuning using the data themselves.
Observations
Model merging can overcome reward hacking (overfitting) of RLHF methods for LLMs.