Summary
Low-rank adaptation (LoRA) is an approach to speed up fine-tuning of neural networks, typically transformers such as language models, originally proposed by (1). In contrast with standard fine-tuning that updates all weights, LoRa updates only a few via: where and are two small weight matrices.
Details
- is proposed to be mostly equivalent to (the derivative of that is typically calculated during backdrop)
- and will have a shape and where is much less than or
- In practice, the new weight matrix can be kept separate from the original matrix
- Two hyper parameters:
- : The rank of the LoRA matrices
- : Scales the influence of the matrices relative to the original weight matrix
Figures
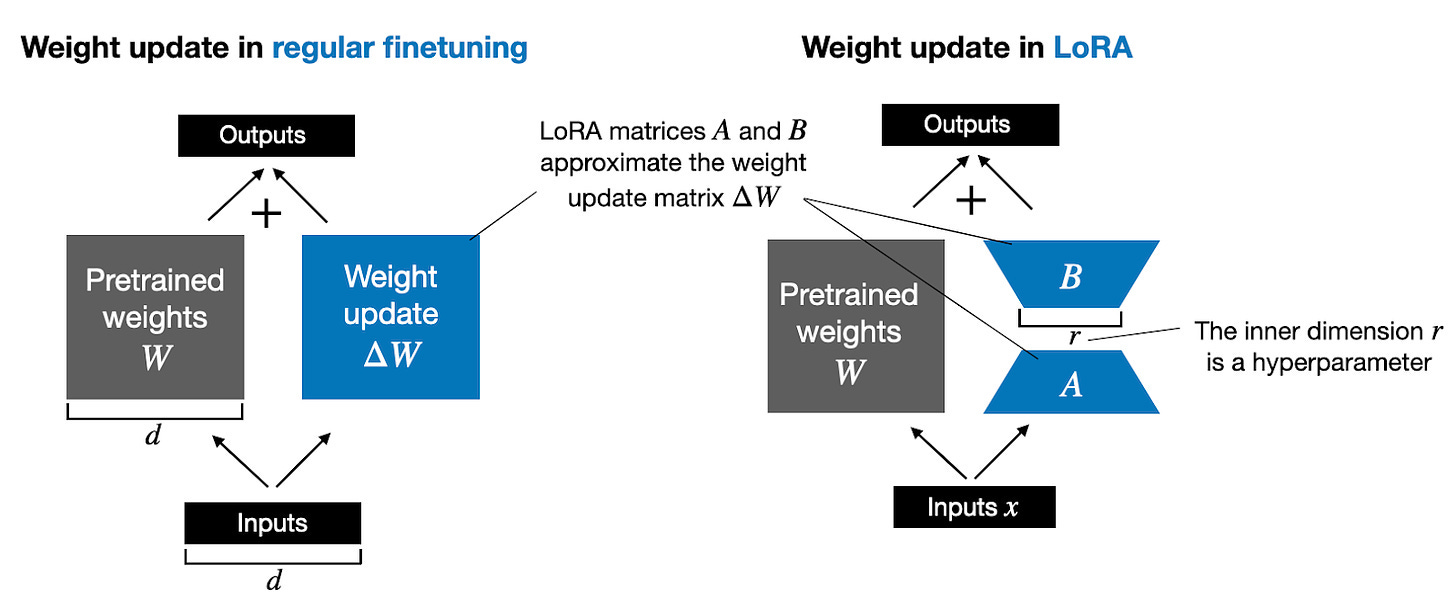 From https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
From https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
See also
- Low-rank adaptation changes the magnitude, but not directionality, of matrix operations relative to fine-tuning
- Low-rank adaptation causes models to learn less and forget less
- Different versions of low-rank adaptation have equivalent performance after controlling for learning rate
- Language models can be infused with structure via low-rank adapter layers
1.
Hu EJ, Shen Y, Wallis P, Allen-Zhu Z, Li Y, Wang S, et al. LoRA: Low-Rank Adaptation of Large Language Models. In: ICLR 2022. 2022. Available from: https://openreview.net/forum?id=nZeVKeeFYf9