Summary
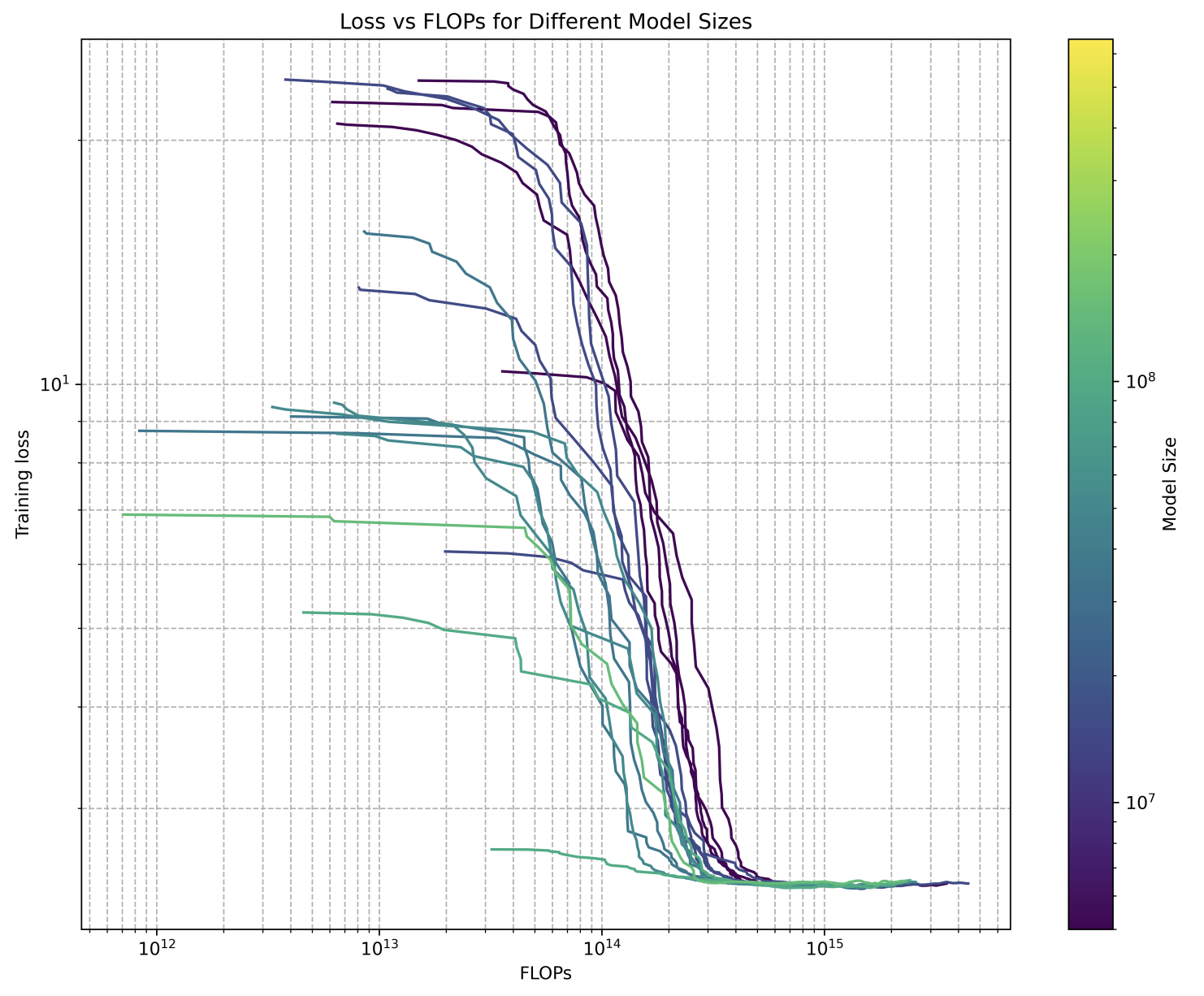
Protein language models achieve a lower bound on pretraining loss, regardless of model size.
Figures
 Ref (1)
Ref (1)
1.
Serrano Y, Ciudad Á, Molina A. Are Protein Language Models Compute Optimal? 2024; Available from: https://arxiv.org/abs/2406.07249