ProteinNPT is a module that can be appended to MSA-based protein language models that was first introduced by (1).
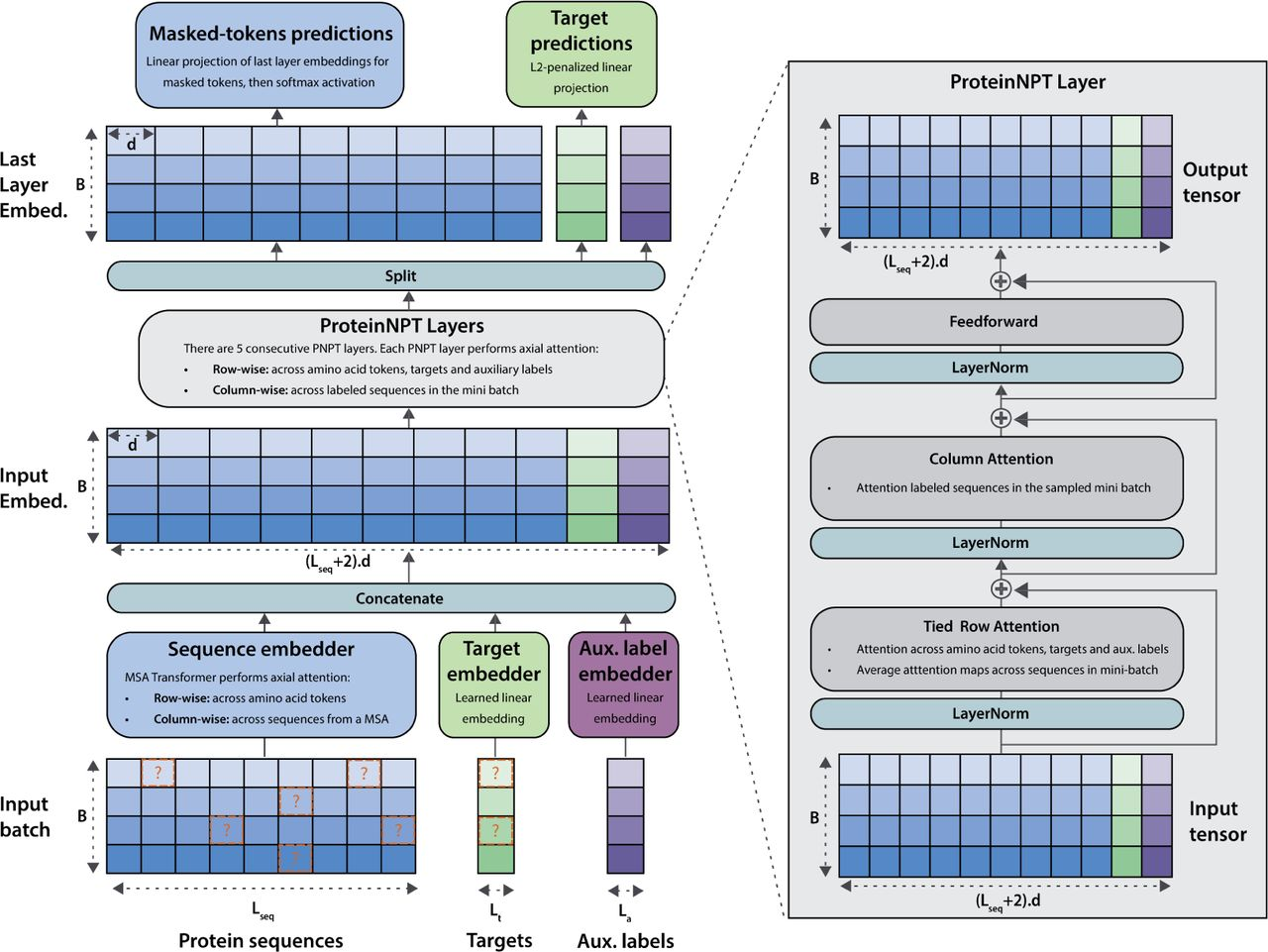 Figure 1 from Notin et al. (1)
Figure 1 from Notin et al. (1)
Notes:
- The method consists of five layers appended to, in the case of the paper, MSA Transformer, which is frozen throughout training. They compare against one-hot encoded representations
- Relevant data to predict is appended as columns. Additional columns that are not relevant for prediction but nonetheless correlate with the property of interest are also added (“Auxiliary labels”)
- The method is re-trained for every MSA/target/set of data using 15% masking as with ESM. At the start of training, the loss is mostly focused on recovering the masked amino acids, but as training proceeds the loss shifts toward recovering the labels
- As with MSA-Transformer, it uses tied row attention to reduce memory footprint under the assumption that the fold is conserved among aligned sequences
- ProteinNPT with Tranception embeddings had the best performance on prediction of catalytic efficiency ():
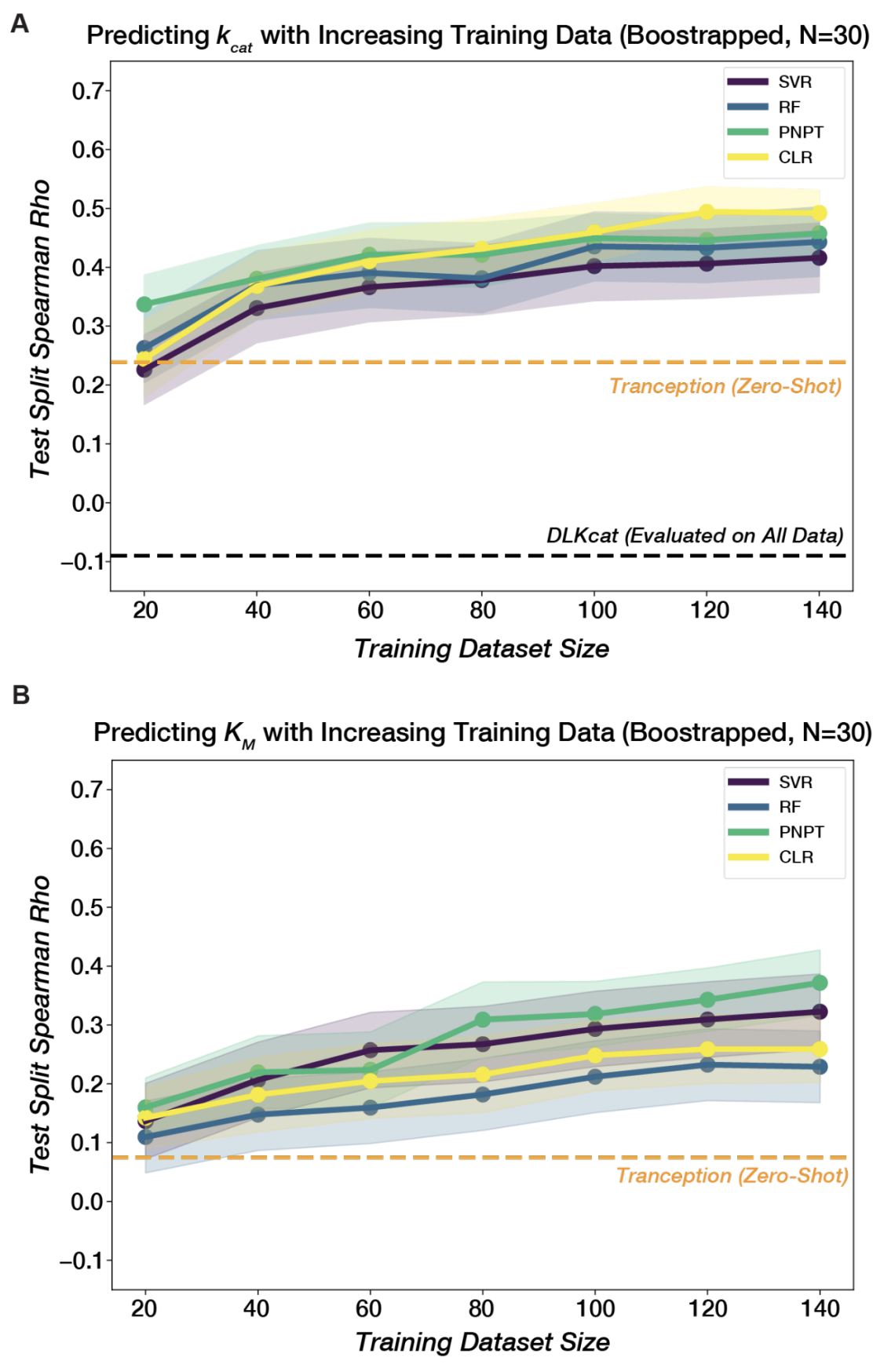 Ref (2)
Ref (2)
1.
Notin P, Weitzman R, Marks DS, Gal Y. ProteinNPT: Improving Protein Property Prediction and Design with Non-Parametric Transformers. openRxiv; 2023. Available from: https://doi.org/10.1101/2023.12.06.570473
2.
Muir DF, Asper GPR, Notin P, Posner JA, Marks DS, Keiser MJ, et al. Evolutionary-scale enzymology enables exploration of a rugged catalytic landscape. Science. 2025;388(6752). Available from: https://doi.org/10.1126/science.adu1058