Summary
Weight-decomposed low-rank adaptation (abbreviated DoRA) is a modification of Low-rank Adaptation introduced by (1) that first decomposes the modified weights into a directional matrix and a magnitude vector. For a constant rank, this adds slightly more parameters, but the authors found that rank can be halved relative to DoRA without any issue and that it made the method more robust in general.
Code
class LinearWithDoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
# dynamic normalization
self.m = nn.Parameter(
self.linear.weight.norm(p=2, dim=0, keepdim=True))
# Code loosely inspired by
# https://github.com/catid/dora/blob/main/dora.py
def forward(self, x):
lora = self.lora.A @ self.lora.B
numerator = self.linear.weight + self.lora.alpha*lora.T
denominator = numerator.norm(p=2, dim=0, keepdim=True)
directional_component = numerator / denominator
new_weight = self.m * directional_component
return F.linear(x, new_weight, self.linear.bias)Code from https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
Figures
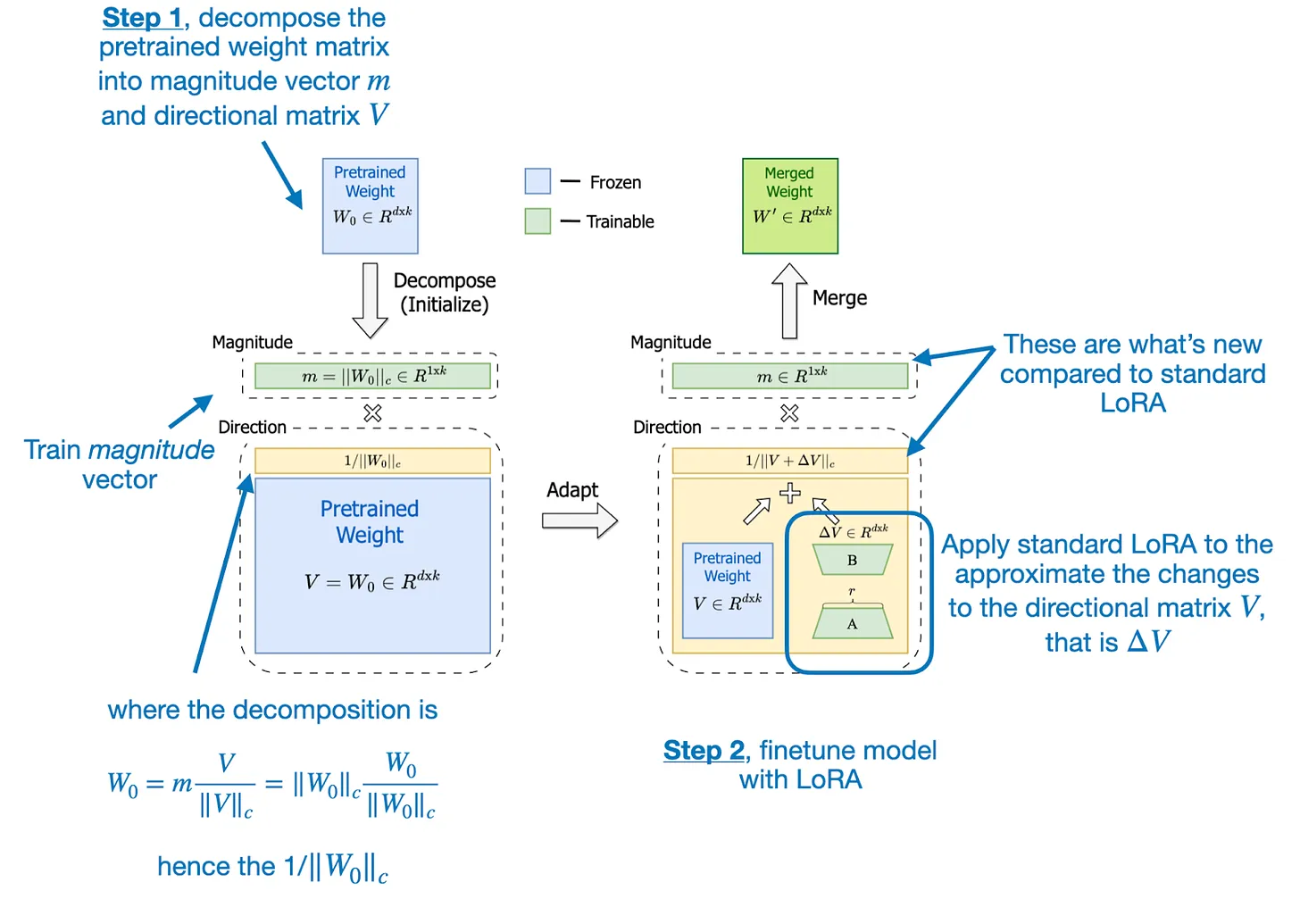 Ref https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
Ref https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
1.
Liu S-Y, Wang C-Y, Yin H, Molchanov P, Wang Y-CF, Cheng K-T, et al. DoRA: Weight-Decomposed Low-Rank Adaptation. In: International Conference on Machine Learning. PMLR; 2024. p. 32100–21. Available from: https://proceedings.mlr.press/v235/liu24bn.html