Summary
Fine-tuning PLMs can be detrimental to downstream tasks. (1) say that it “should therefore take place only under rigorous cross validation.” (2) found evidence of Catastrophic forgetting during fine-tuning of their PLM on Foldseek structural descriptors. (3) avoided this by maintaining the pretraining objective and data when fine-tuning; in their case keeping unpaired antibody sequences while fine-tuning on paired sequences.
Details
Beyond protein ML models, RLHF was also found to worsen performance of the large language model GPT-4 (4).
Figures
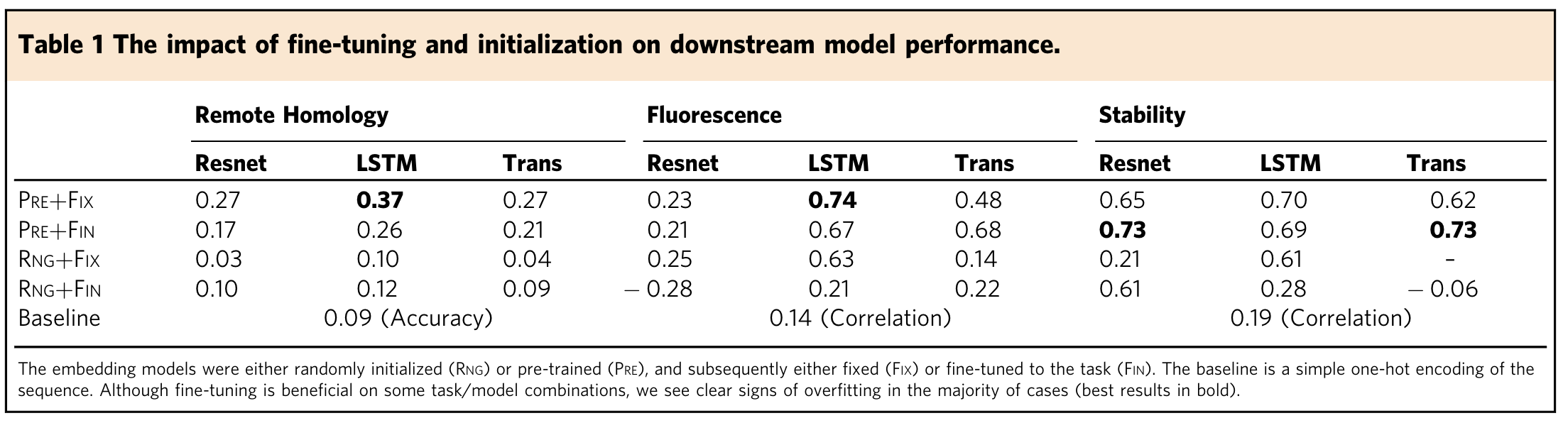 Ref (1)
Ref (1)
1.
Detlefsen NS, Hauberg S, Boomsma W. Learning meaningful representations of protein sequences. Nature Communications. 2022;13(1). Available from: https://doi.org/10.1038/s41467-022-29443-w
2.
Heinzinger M, Weissenow K, Sanchez JG, Henkel A, Mirdita M, Steinegger M, et al. Bilingual language model for protein sequence and structure. NAR Genomics and Bioinformatics. 2024;6(4). Available from: https://doi.org/10.1093/nargab/lqae150
3.
Kenlay H, Dreyer FA, Kovaltsuk A, Miketa D, Pires D, Deane CM. Large scale paired antibody language models. PLOS Computational Biology. 2024;20(12):e1012646. Available from: https://doi.org/10.1371/journal.pcbi.1012646
4.
Chen L, Zaharia M, Zou J. How Is ChatGPT’s Behavior Changing Over Time? Harvard Data Science Review. 2024;6(2). Available from: https://doi.org/10.1162/99608f92.5317da47