Summary
Masked language models (such as BERT) can be fine-tuned starting from autoregressive models (such as GPT) in ways that benefit from scale, but not vice-versa (1). This was demonstrated using protein language models.
Figures
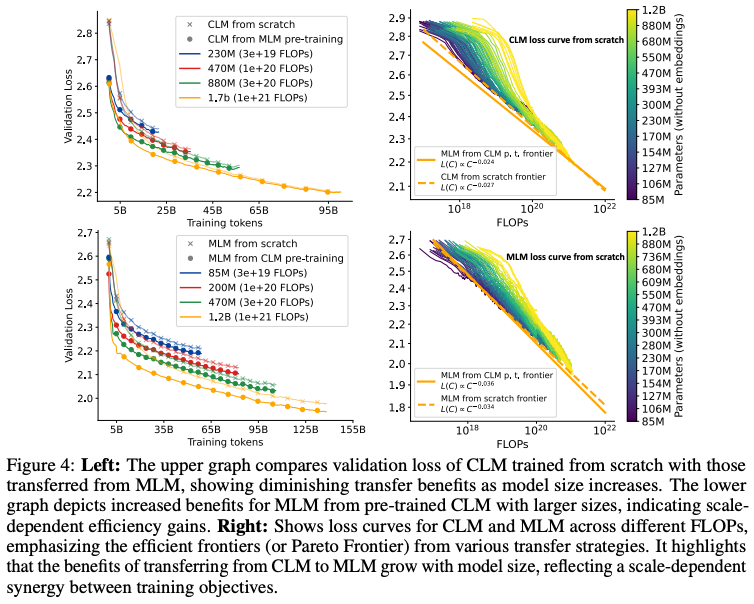 Ref (1)
Ref (1)
See also
1.
Cheng X, Chen B, Li P, Gong J, Tang J, Song L. Training Compute-Optimal Protein Language Models. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.06.06.597716