Summary
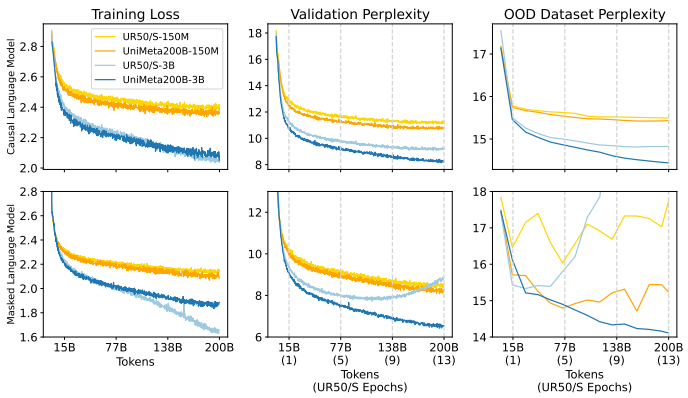
Masked PLMs (such as ESM) are more sensitive to training imbalances than autoregressive models (such as ProGen; (1)). Presumably this is also true of transformers trained on natural language.
Figures
 Ref (1)
Ref (1)
See also
1.
Cheng X, Chen B, Li P, Gong J, Tang J, Song L. Training Compute-Optimal Protein Language Models. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.06.06.597716