Summary
PLMs are biased by the fact that sequence databases used for training are unevenly distributed toward prokaryotes (1,2). This bias is stronger for larger models and stronger for ProGen than ESM, with the former being trained on UniRef90 and the latter on UniRef50. Augmenting these datasets with metagenomic data can improve generalization (but it is unclear if it would fix this problem specifically; (3)).
Details
Most organisms only have a few proteins assigned to them (2).
Figures
| Model | R²_species | R²_protein | R²_both | R²_S|P |
|---|---|---|---|---|
| PROGEN2-XLARGE | 0.50 | 0.42 | 0.81 | 0.67 |
| PROGEN2-BFD90 | 0.49 | 0.51 | 0.85 | 0.69 |
| PROGEN2-LARGE | 0.46 | 0.60 | 0.87 | 0.67 |
| PROGEN2-BASE | 0.25 | 0.64 | 0.84 | 0.55 |
| PROGEN2-MEDIUM | 0.44 | 0.59 | 0.86 | 0.66 |
| ESM2-15B | 0.25 | 0.42 | 0.60 | 0.32 |
| ESM2-3B | 0.26 | 0.46 | 0.63 | 0.32 |
| ESM2-650M | 0.19 | 0.62 | 0.72 | 0.26 |
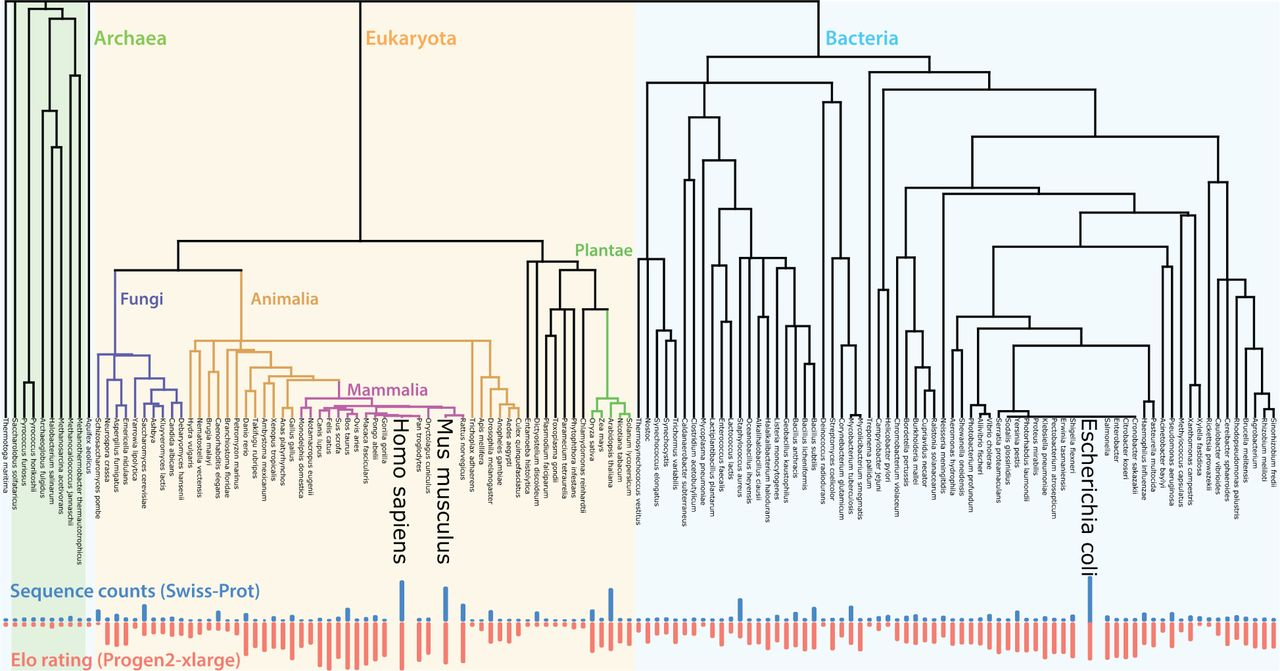
Figures from (1)
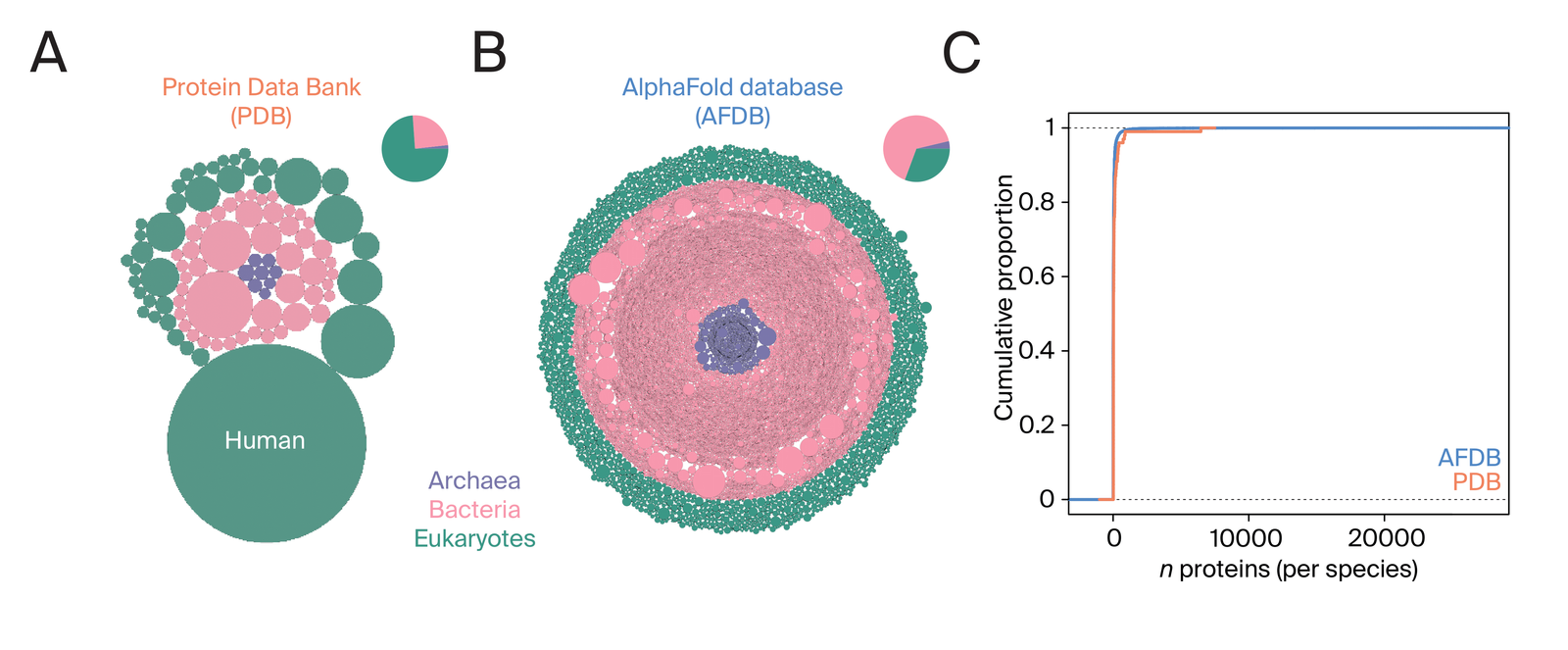
Ref (2)
See also
- Unbalanced composition of sequence data prevents protein fitness from being identifiable from sequence data alone
- Protein property prediction using PLMs does not benefit from scale except when predicting inferring features of either structural or sparsely populated sequence families
- ML models must trade off bias and variance
1.
Ding F, Steinhardt J. Protein language models are biased by unequal sequence sampling across the tree of life. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.03.07.584001
2.
Avasthi P, York R. The known protein universe is phylogenetically biased. 2024; Available from: https://thestacks.org/publications/result-protein-universe-phylogenetic-bias
3.
Cheng X, Chen B, Li P, Gong J, Tang J, Song L. Training Compute-Optimal Protein Language Models. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.06.06.597716