Summary
Synthetic data over-represents mean values of the original data distribution and either underrepresents or exaggerates the presence of outliers (1). This can pose a challenge for models trained using Distillation and can be a cause of Catastrophic forgetting.
Figures
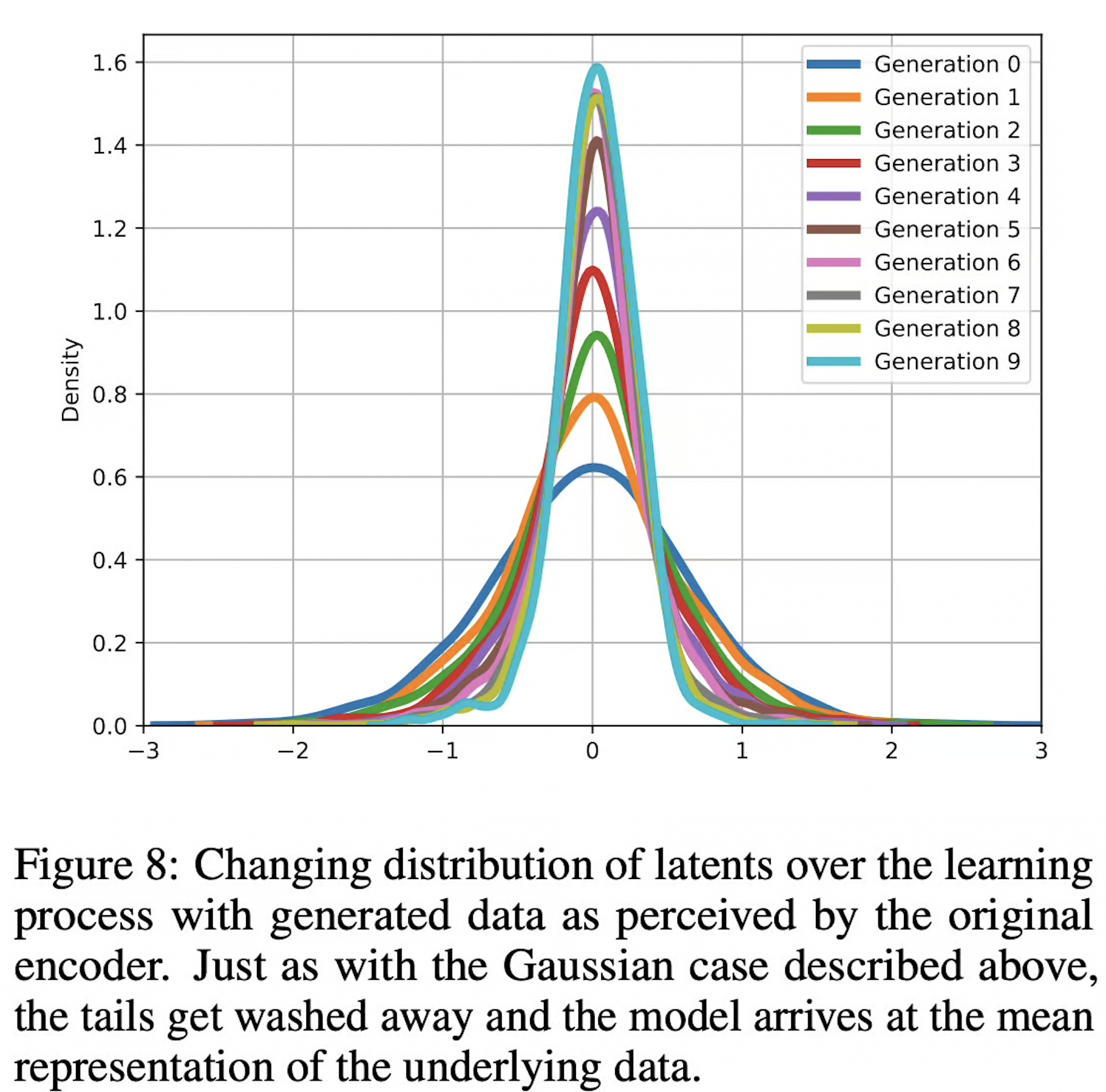 Ref (1)
Ref (1)
See also
- Training inverse folding and diffusion models exclusively on predicted protein structures worsens performance due to how locally perfect they are
- ML models trained exclusively on experimental structures are less effective on computational models
1.
Shumailov I, Shumaylov Z, Zhao Y, Gal Y, Papernot N, Anderson R. The Curse of Recursion: Training on Generated Data Makes Models Forget. 2023; Available from: https://arxiv.org/abs/2305.17493