Summary
PLM embeddings contain enough information to be aligned without fine-tuning (1), and these alignments outperform purely sequence-based but not structure-based methods ((2), (3)). This could be since the embeddings of aligned positions in related sequences tend to co-cluster (4). Alignment quality can be further improved by normalization (5), which does not require PLM fine-tuning. (6) surmise that the distance matrices implied by these embeddings are more effective than the BLOSUM62 matrix used by many sequence alignments by default.
Details
TM-vec, a fine-tuned model, was found to be worse than non-fine-tuned models (3).
To improve alignment quality using “normalization” (per (5)), all distances (for their paper, Euclidean distances are used) are computed and converted to Z-scores to normalize relative to other entries in the same column and row. This was shown to improve performance relative to using non-normalized/enhanced values for alignment calculation.
Figures
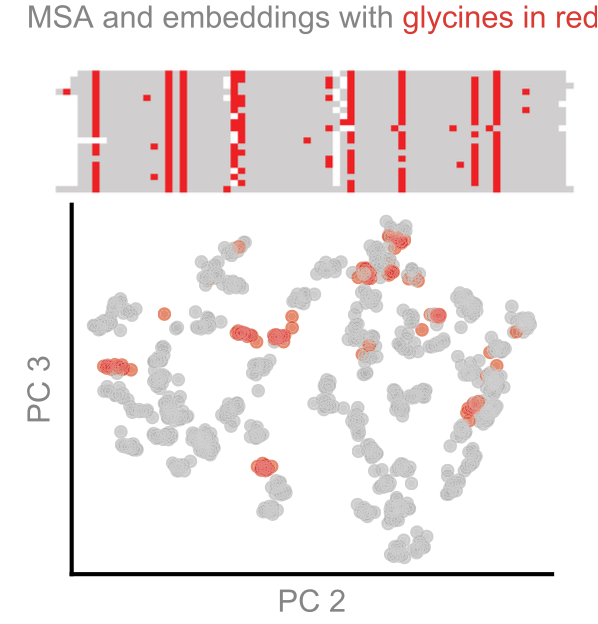 Ref (4)
Ref (4)
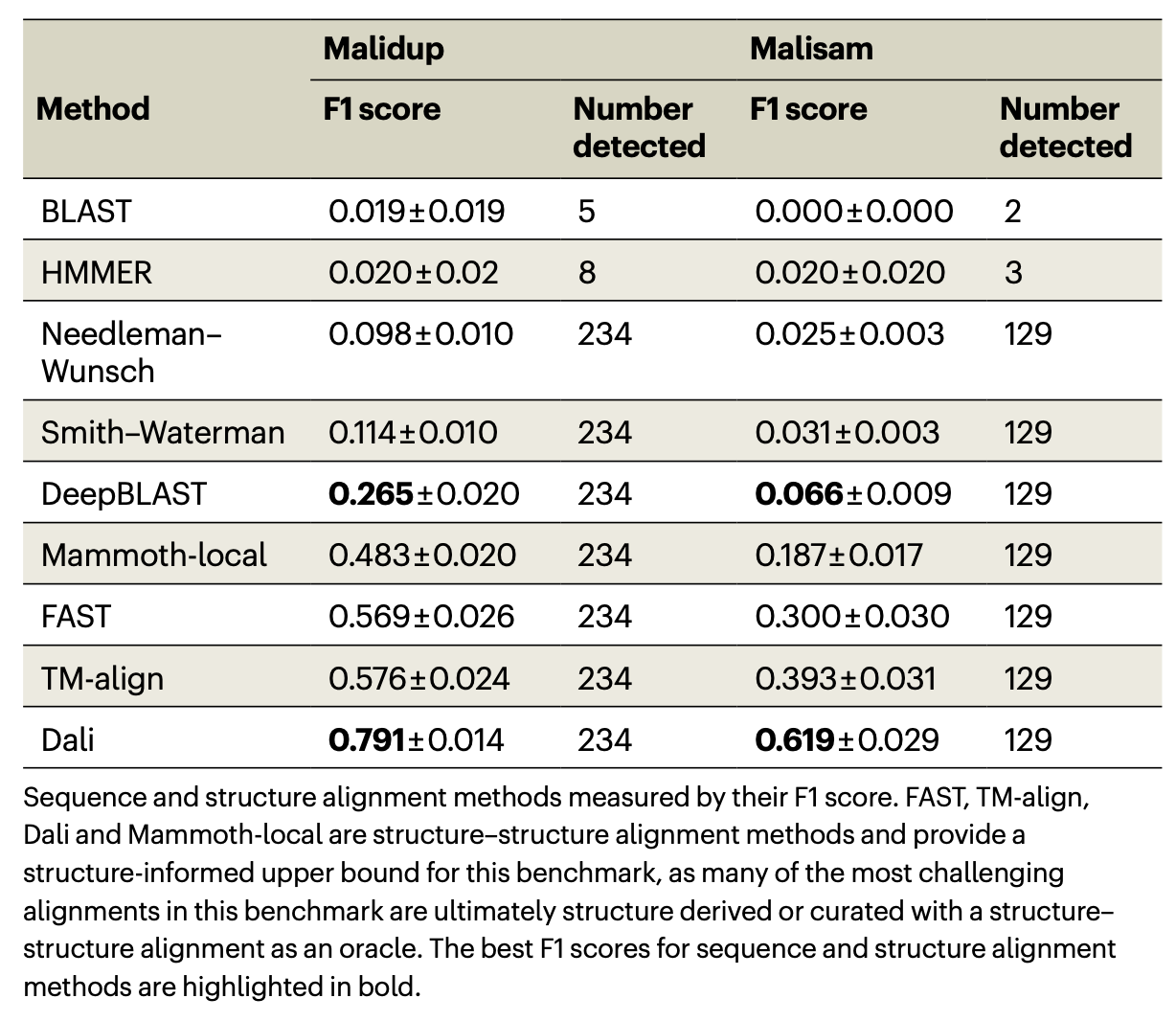 Ref (3)
Ref (3)
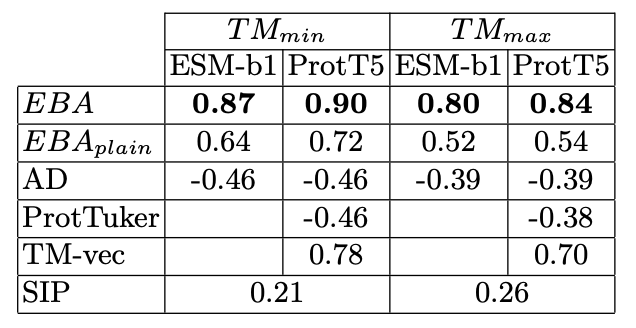 Ref (5); EBA and EBA-plain refer to PLM-based alignment with and without normalization
Ref (5); EBA and EBA-plain refer to PLM-based alignment with and without normalization
See also
- Multiple sequence alignments
- PLMs learn family-specific protein contacts from sequence context windows of about 20-40 amino acids