Summary
Pretraining contributes nearly nothing to performance when fine-tuning protein language models under data-rich conditions (1). This was determined by fine-tuning both pretrained models and randomly initialized equivalents on the same dataset.
Figures
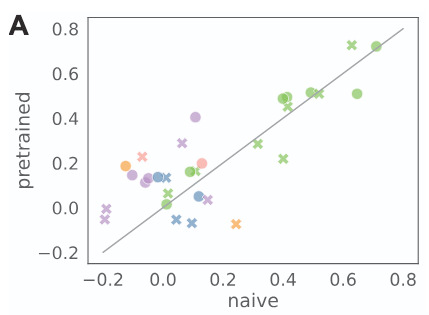 Ref (1)
Ref (1)
1.
Didi K, Alamdari S, Lu AX, Wittmann B, Johnston KE, Amini AP, et al. FLIP2: Expanding Protein Fitness Landscape Benchmarks for Real-World Machine Learning Applications. openRxiv; 2026. Available from: https://doi.org/10.64898/2026.02.23.707496