Summary
Base protein language models must usually be fine-tuned to generate functionally active sequences (1,2). (3) showed that, in a head-to-head between an unspecified foundation model and its “evo-tuned” derivative, the latter was better at variant effect prediction. Note that this is not true of models where functional annotations can be provided, such as ZymCTRL (2) and ESM3 (4).
Details
Fannjiang and (5) give several citations for how pan-protein data is unnecessary for generating novel sequences. Evo-tuning was first presented by (6)
Figures
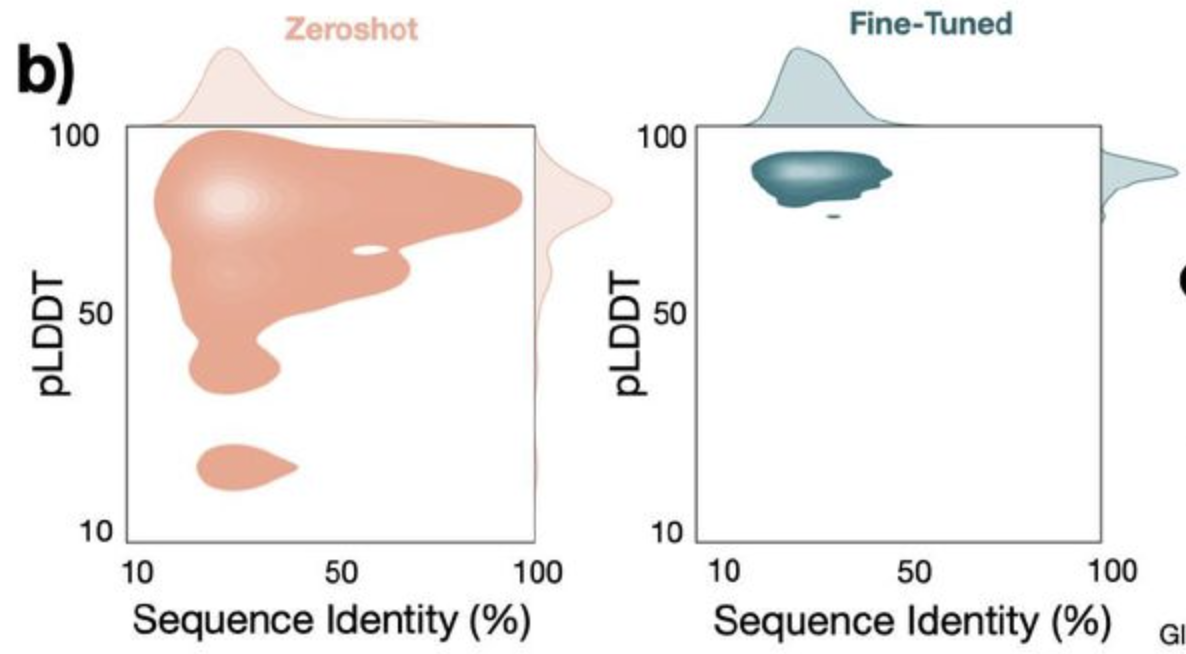 Ref
Ref 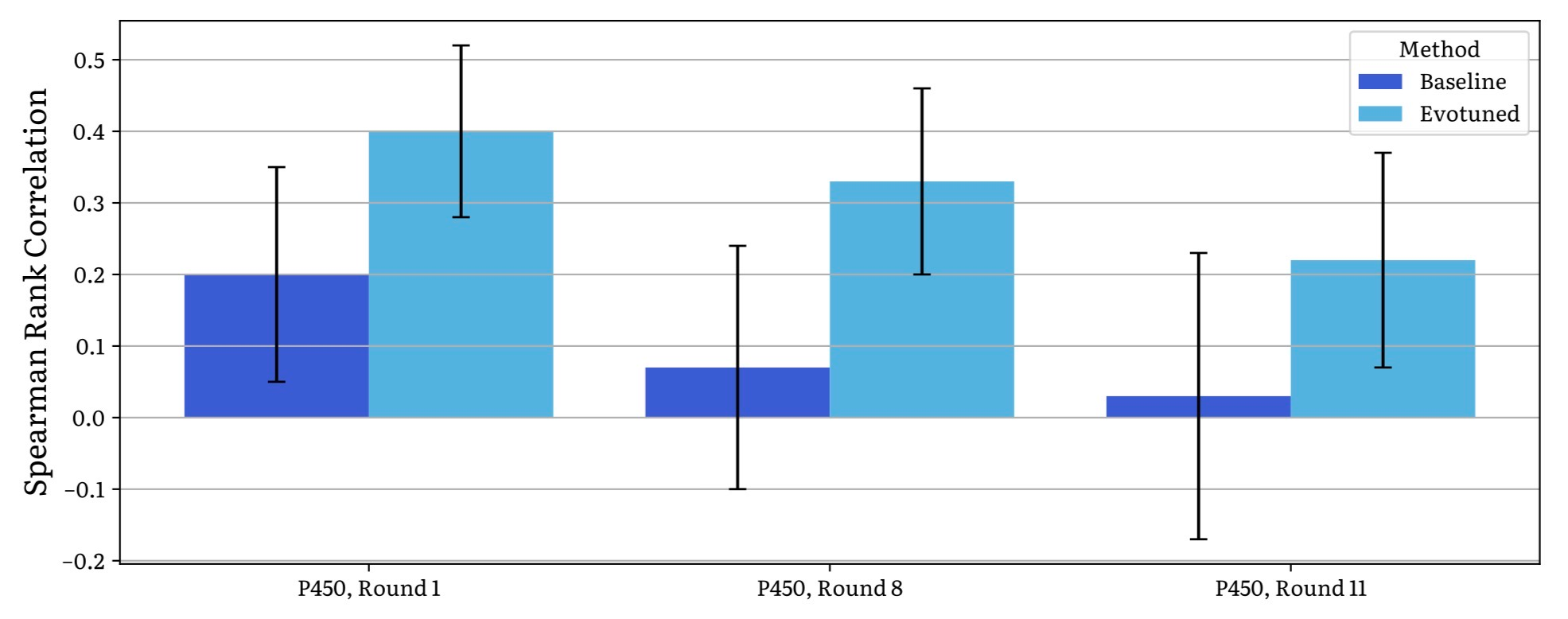 Ref
Ref See also
- Protein language models make equally effective predictions when trained on individual proteins or protein families
- Pretraining contributes nearly nothing to performance when fine-tuning protein language models in data-rich situations
- Fine-tuning base models on test cases can improve the performance of variant effect and structure prediction
1.
Madani A, Krause B, Greene ER, Subramanian S, Mohr BP, Holton JM, et al. Large language models generate functional protein sequences across diverse families. Nature Biotechnology. 2023;41(8):1099–106. Available from: https://doi.org/10.1038/s41587-022-01618-2
2.
Munsamy G, Illanes-Vicioso R, Funcillo S, Nakou IT, Lindner S, Ayres G, et al. Conditional language models enable the efficient design of proficient enzymes. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.05.03.592223
3.
Bixby E, Brunner G, Danciu D, Dela Rosa R, Deutschmann N, Ferragu C, et al. What comes after de novo ? Automated lead optimization of proteins with CRADLE-1. openRxiv; 2026. Available from: https://doi.org/10.64898/2026.03.06.710001
4.
Hayes T, Rao R, Akin H, Sofroniew NJ, Oktay D, Lin Z, et al. Simulating 500 million years of evolution with a language model. Science. 2025;387(6736):850–8. Available from: https://doi.org/10.1126/science.ads0018
5.
Fannjiang C, Listgarten J. Is novelty predictable? arXiv. 2023; Available from: https://arxiv.org/abs/2306.00872
6.
Biswas S, Khimulya G, Alley EC, Esvelt KM, Church GM. Low-N protein engineering with data-efficient deep learning. Nature Methods. 2021;18(4):389–96. Available from: https://doi.org/10.1038/s41592-021-01100-y