Summary
Reinforcement learning (here, DPO) outperforms fine-tuning on property-guided inverse folding (1). This was shown using (ProteinMPNN) as a base model, and even in situations with multiple constraints. As shown below, this does not lead to sacrificed refoldability metrics.
Figures
| Method | RMSD ↓ | TM score ↑ | PLDDT ↑ | EP ↓ | Sol ↑ | Thermo ↑ | AAR ↑ |
|---|---|---|---|---|---|---|---|
| Test Dataset | 3.97 | 0.761 | 80.8 | 5.80 | 0.620 | 0.246 | 1.000 |
| ESM-IF | 4.36 | 0.737 | 78.4 | 6.11 | 0.733 | 0.719 | 0.464 |
| InstructPLM (default) | 6.81 | 0.628 | 73.4 | 7.97 | 0.653 | 0.396 | 0.574 |
| InstructPLM (T=0.1) | 6.96 | 0.632 | 74.4 | 7.31 | 0.657 | 0.455 | 0.584 |
| ProteinMPNN | 4.30 | 0.740 | 79.1 | 6.70 | 0.719 | 0.769 | 0.389 |
| ProteinDPO | 5.49 | 0.667 | 72.0 | 10.50 | 0.629 | 0.357 | 0.388 |
| SolubleMPNN | 4.48 | 0.733 | 78.8 | 6.54 | 0.794 ★ | 0.815 | 0.382 |
| Guidance [Sol] | 4.33 | 0.740 | 79.4 | 6.40 | 0.762 ★ | 0.805 | 0.393 |
| MoMPNN [Sol+TM] | 4.37 | 0.738 | 79.3 | 6.27 | 0.884 ★ | 0.747 | 0.384 |
| MoMPNN [Sol+TM+EP] | 4.38 | 0.739 | 79.5 | 6.18 | 0.852 ★ | 0.790 | 0.387 |
| MoMPNN [Sol+IG] | 4.73 | 0.727 | 79.3 | 6.00 | 0.883 ★ | 0.751 | 0.382 |
| MoMPNN [Sol+IG+EP] | 4.61 | 0.731 | 79.3 | 5.99 | 0.856 ★ | 0.789 | 0.384 |
| HyperMPNN | 4.90 | 0.706 | 74.3 | 7.81 | 0.719 | 0.929 ★ | 0.359 |
| Guidance [Thermo] | 4.30 | 0.737 | 77.6 | 6.88 | 0.735 | 0.901 ★ | 0.386 |
| MoMPNN [Thermo+TM] | 4.30 | 0.739 | 78.4 | 6.24 | 0.704 | 0.947 ★ | 0.386 |
| MoMPNN [Thermo+TM+EP] | 4.30 | 0.742 | 78.6 | 6.12 | 0.731 | 0.946 ★ | 0.387 |
| MoMPNN [Thermo+IG] | 4.38 | 0.734 | 78.2 | 5.85 | 0.694 | 0.963 ★ | 0.382 |
| MoMPNN [Thermo+IG+EP] | 4.37 | 0.737 | 78.5 | 5.97 | 0.723 | 0.947 ★ | 0.385 |
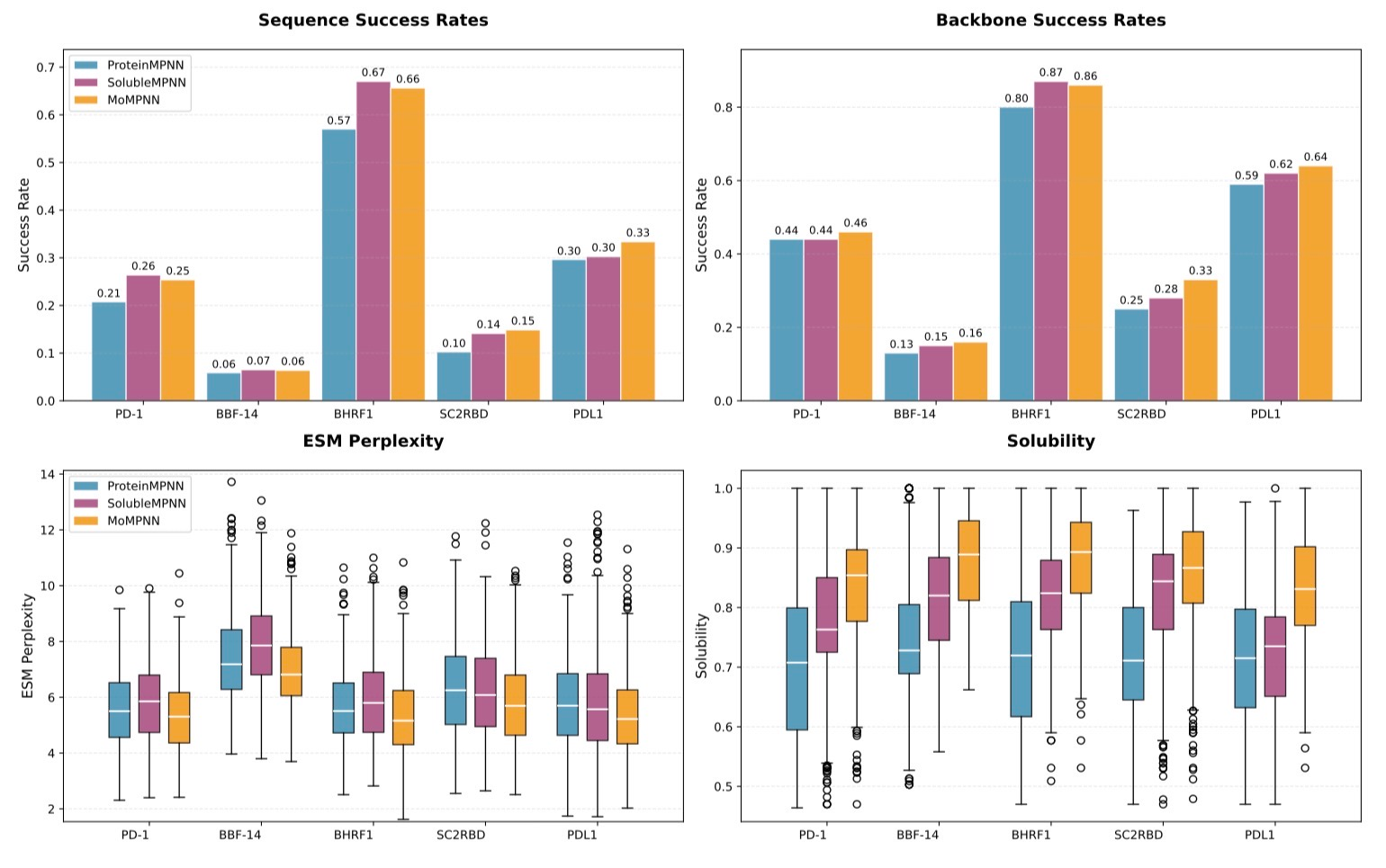 | |||||||
| Ref (1) |
1.
Hou X, Liu J, Shi C, Liu X, Yang Z, Tang J. Property-driven Protein Inverse Folding With Multi-Objective Preference Alignment. 2026; Available from: https://arxiv.org/abs/2603.06748