Summary
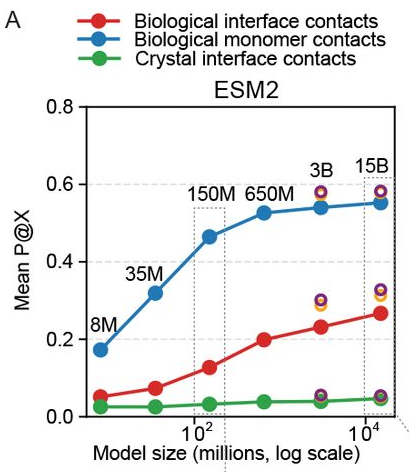
Sequence-only protein language models implicitly cluster protein sequences at fineness granularities that increase with size (1). For example, ESM-15B implicitly learns about sequence constraints from very similar proteins, whereas the 650M model learns from a broader pool of sequences. This was determined by observing the extent to which these models learn homo-oligomeric contacts and comparing their performance to that of MSA-Pairformer.
Figures
 Ref (1)
Ref (1)
See also
- Protein property prediction using PLMs does not benefit from scale except when predicting inferring features of either structural or sparsely populated sequence families
- Larger PLMs generate more novel sequences from more sparsely populated protein families
1.
Zhang Z, Akiyama Y, Cho Y, Jajoo S, Ovchinnikov S. Hit or Miss: Understanding Emergence and Absence of Homo-oligomeric Contacts in Protein Language Models. openRxiv; 2025. Available from: https://doi.org/10.1101/2025.11.16.688745