Summary
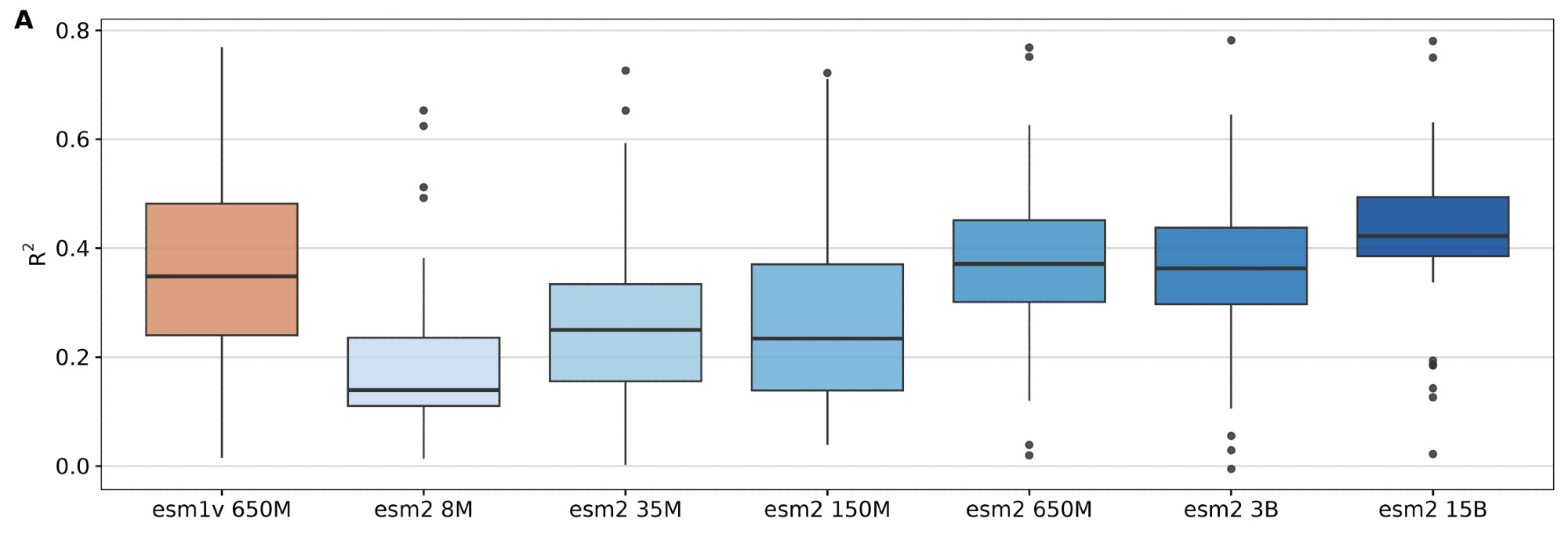
Protein property prediction using PLMs does not benefit from scale beyond ~650M parameters, except when predicting A) structural features or B) features of sparsely populated protein families such as those from viruses. This is particularly the case with zero-shot prediction (1–2). Some authors have reported it is also true of fine-tuning (4–5), although aligning PLMs using reinforcement learning using data does seem to restore the trend in some cases (7). The exception of structure when transfer learning was shown by (5), and corroborated by attempts to use (ESM) embeddings as starting points for structure prediction (8,9). Related to this, larger PLMs are better at homolog detection and thermostability prediction, and do not improve as much as smaller models at fitness prediction when infused with structural information via low-rank adaptors (10). Likewise, the exception for viral proteins was observed by (11). (12) surmise that both exceptions are due to large PLMs having a greater capacity to memorize domain-specific contacts.
Details
Larger (ProGen) models were better able to predict fitness of distant sequences (“wide mutational scale”; (2)). Likewise, engineered CRISPR variants were said to be better predicted with larger models ((13); mentioned at PEGS Boston 2024). Augmenting ProGen models with structural information only led to improvements in fitness prediction in smaller models, suggesting that the larger models had already learned most of that information.
This is also true of post-translational modification prediction ((14); ESM2-650M vs ESM2-3B).
Figures
| Model type | Model name | Spearman | AUC | MCC | NDCG | Recall |
|---|---|---|---|---|---|---|
| Alignment-based | Site-Independent | 0.361 | 0.697 | 0.288 | 0.746 | 0.201 |
| WaveNet | 0.216 | 0.623 | 0.174 | 0.684 | 0.154 | |
| EVmutation | 0.397 | 0.717 | 0.306 | 0.775 | 0.220 | |
| DeepSequence (ens.) | 0.422 | 0.731 | 0.330 | 0.775 | 0.227 | |
| EVE (ens.) | 0.441 | 0.741 | 0.343 | 0.781 | 0.231 | |
| GEMME | 0.457 | 0.750 | 0.353 | 0.775 | 0.209 | |
| Protein language | UniRep | 0.193 | 0.607 | 0.149 | 0.647 | 0.14 |
| CARP (640M) | 0.373 | 0.704 | 0.289 | 0.749 | 0.210 | |
| RITA XL | 0.373 | 0.708 | 0.294 | 0.750 | 0.194 | |
| ProGen2 XL | 0.392 | 0.718 | 0.307 | 0.766 | 0.200 | |
| ESM-1b ★ | 0.399 | 0.722 | 0.315 | 0.748 | 0.205 | |
| ESM2 (15B) ★ | 0.405 | 0.723 | 0.318 | 0.759 | 0.210 | |
| ESM-1v (ens.) | 0.416 | 0.730 | 0.329 | 0.753 | 0.216 | |
| VESPA | 0.437 | 0.743 | 0.348 | 0.774 | 0.201 | |
| Hybrid | UniRep evotuned | 0.347 | 0.693 | 0.274 | 0.737 | 0.181 |
| MSA Transformer (ens.) | 0.434 | 0.738 | 0.341 | 0.777 | 0.224 | |
| Tranception L | 0.436 | 0.740 | 0.342 | 0.778 | 0.221 | |
| TranceptEVE L | 0.457 | 0.752 | 0.357 | 0.785 | 0.231 | |
| Inverse Folding | ProteinMPNN | 0.258 | 0.640 | 0.196 | 0.712 | 0.186 |
| MIF-ST | 0.401 | 0.718 | 0.310 | 0.766 | 0.227 | |
| ESM-IF1 | 0.422 | 0.730 | 0.331 | 0.748 | 0.223 | |
| Ref (3) |
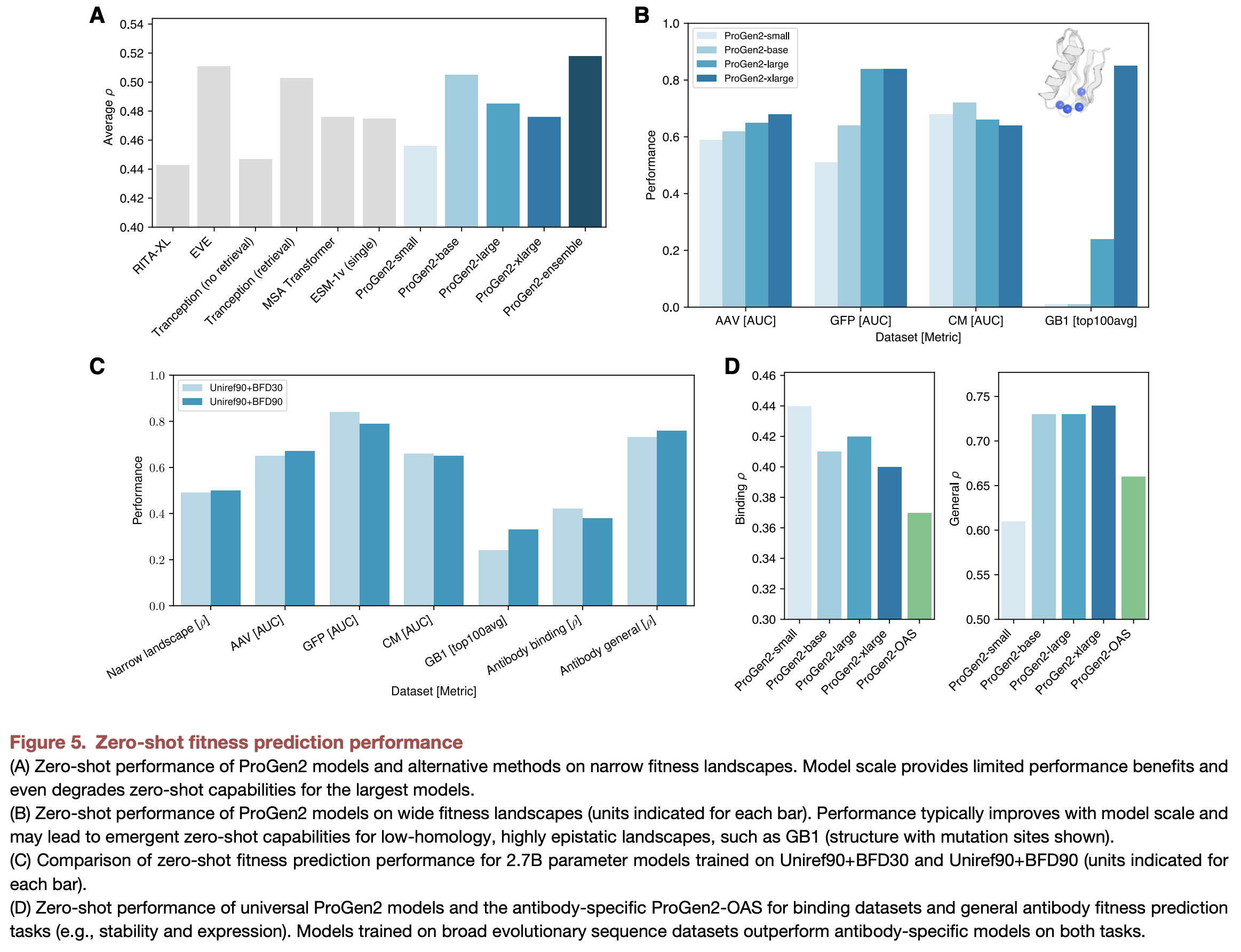 Ref (2)
Ref (2)
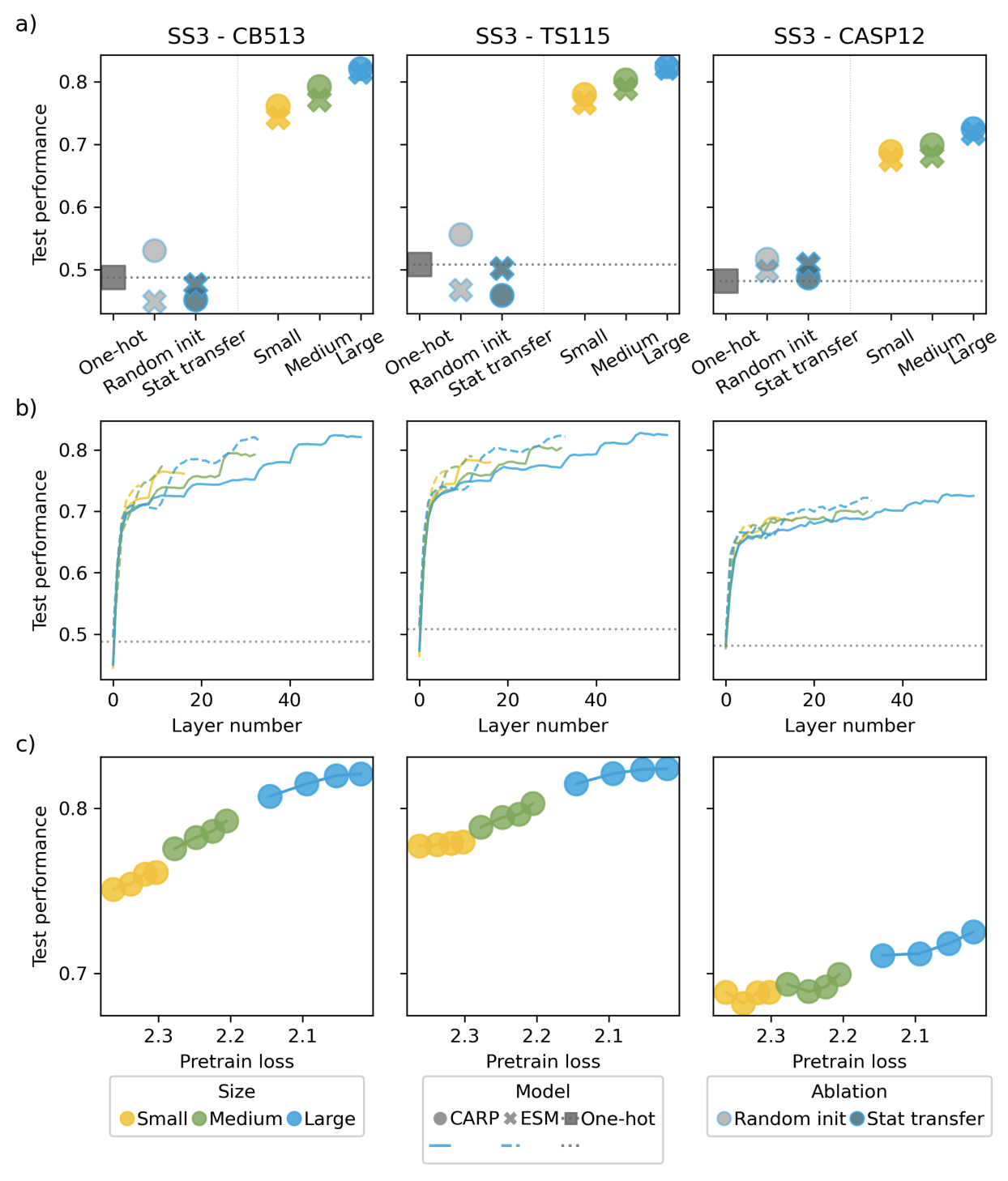
 Figures 3-5 from (5)
Figures 3-5 from (5)
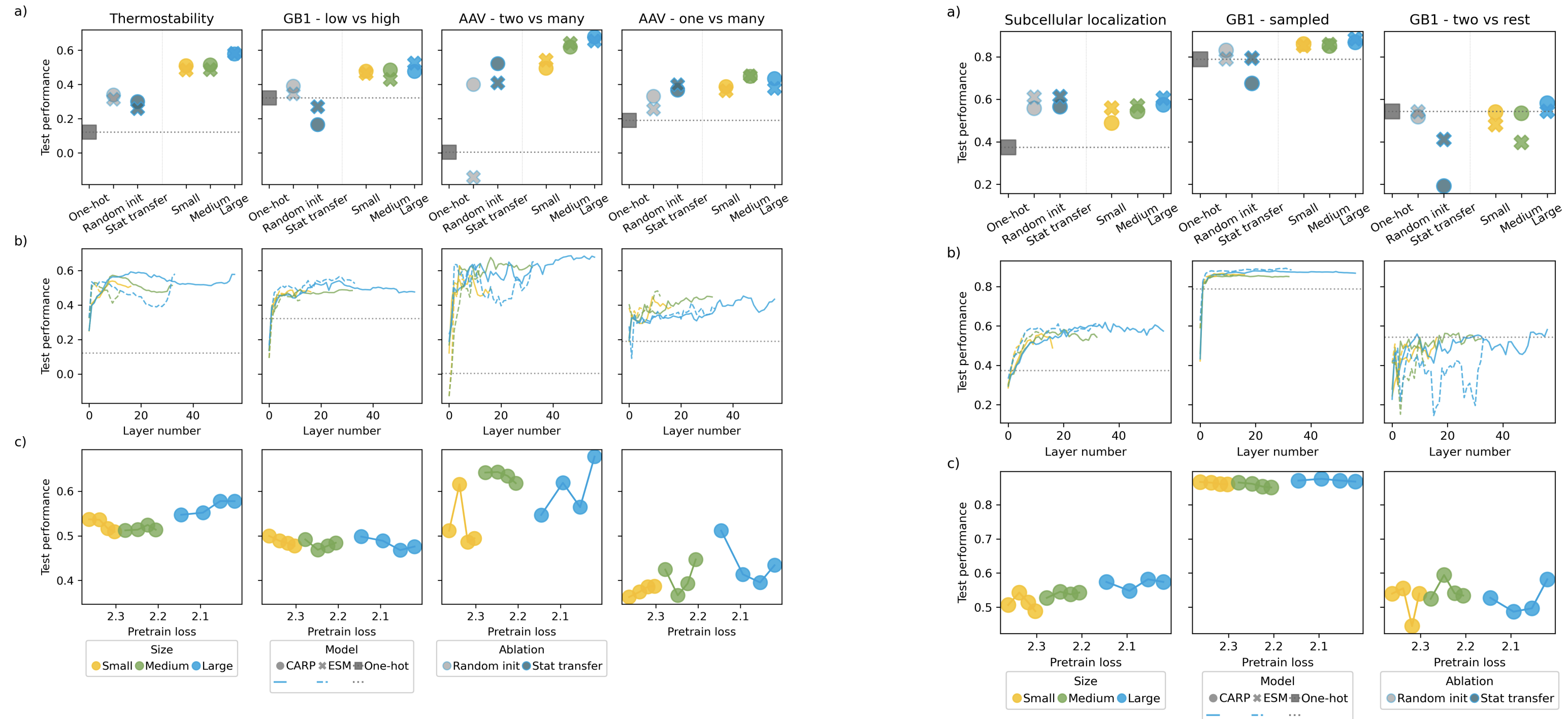
 Ref (6)
Ref (6)
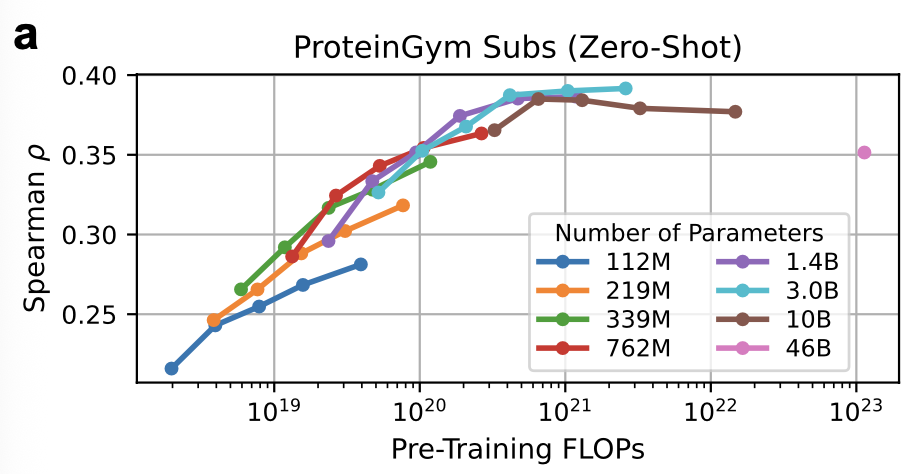 Ref (7)
Ref (7)
.png)
.png) Figures from (11)
Figures from (11)