Summary
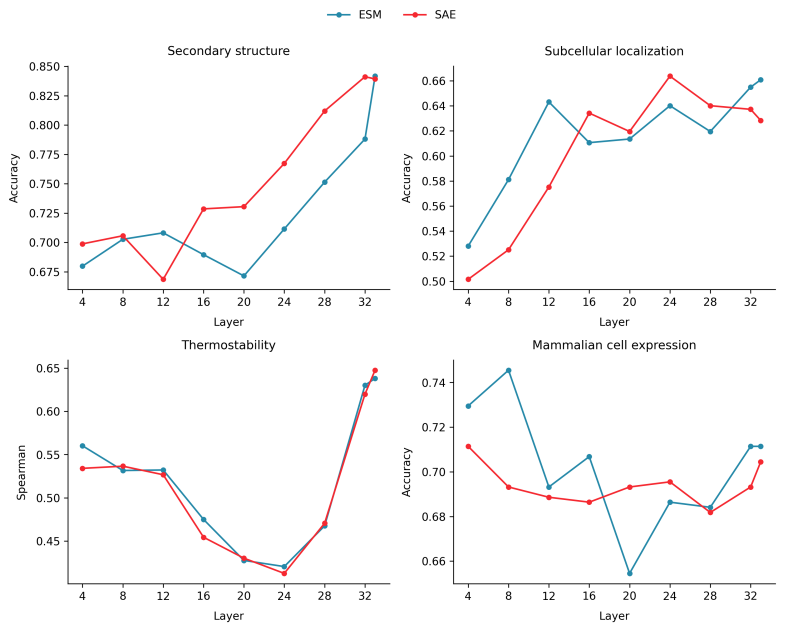
Sparse autoencoder-derived features do not outperform PLM embeddings for downstream prediction (1).
Figures
 Ref (1)
Ref (1)
1.
Adams E, Bai L, Lee M, Yu Y, AlQuraishi M. From Mechanistic Interpretability to Mechanistic Biology: Training, Evaluating, and Interpreting Sparse Autoencoders on Protein Language Models. openRxiv; 2025. Available from: https://doi.org/10.1101/2025.02.06.636901