Summary
The scaling hypothesis says that Transformer models (and deep learning models more broadly) learn a richer understanding of the training data as they and their training sets get larger. (1) give examples for this in natural language processing (below).
Figures
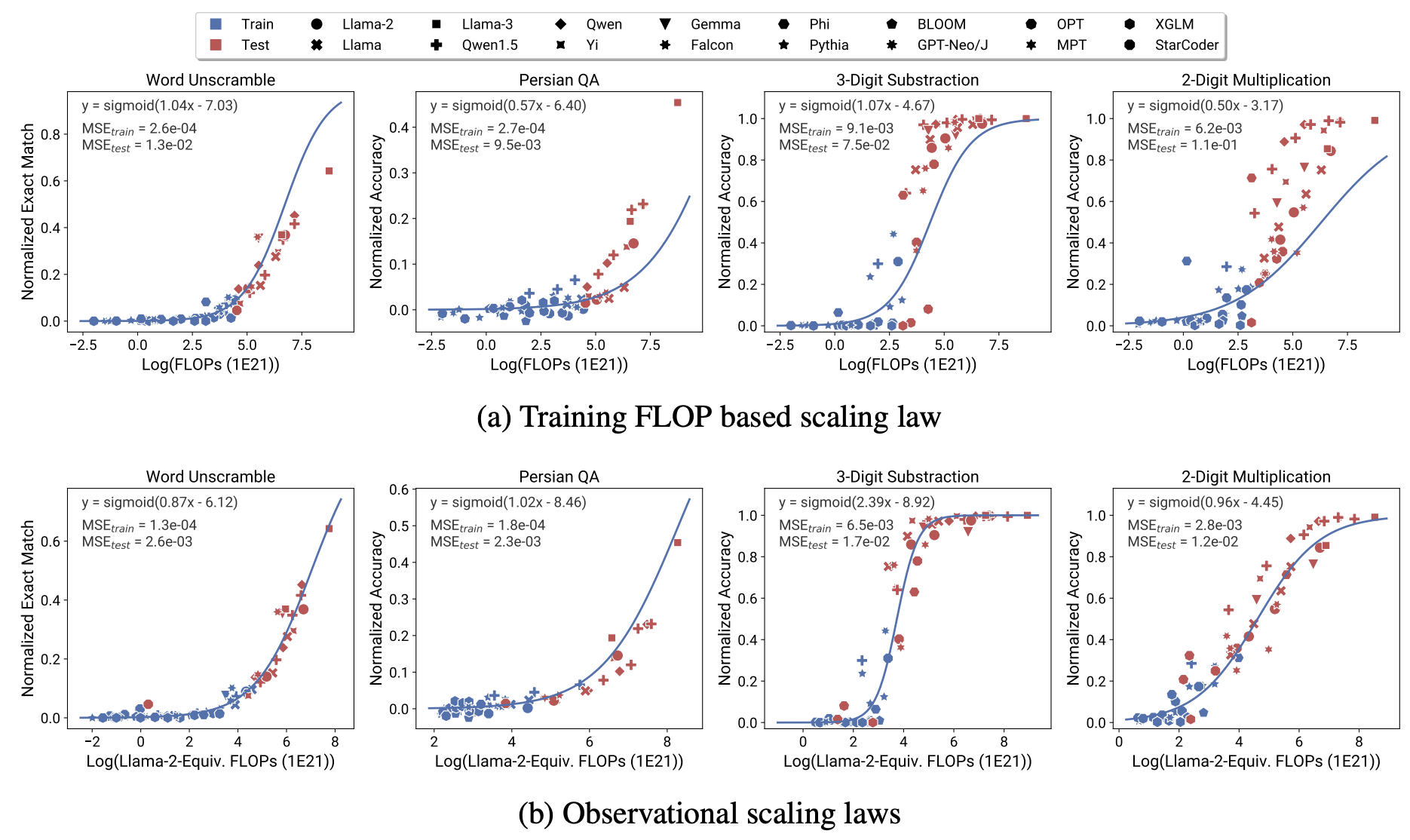 Ref (1)
Ref (1)
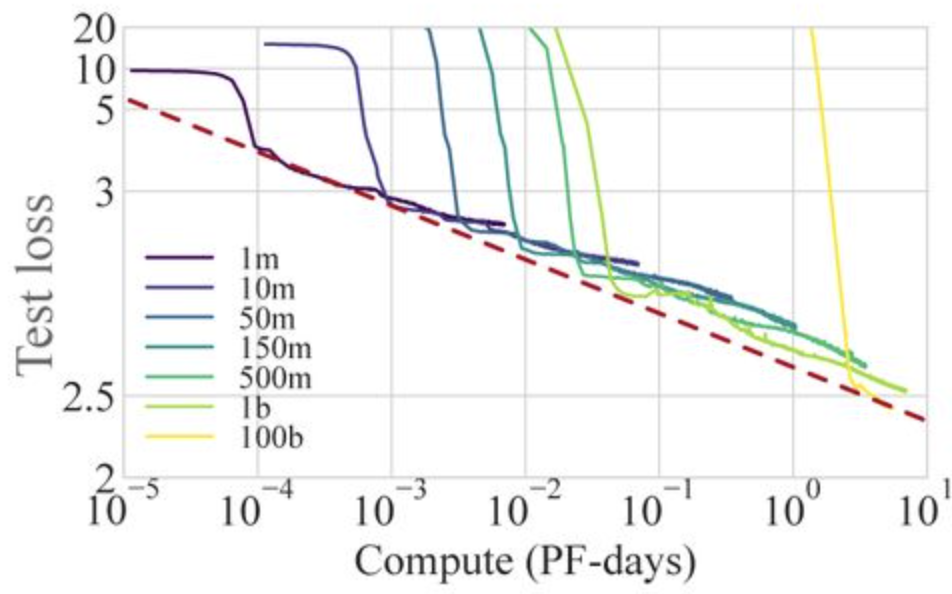 From (2)
From (2)
1.
Ruan Y, Maddison CJ, Hashimoto T. Observational Scaling Laws and the Predictability of Language Model Performance. 2024; Available from: https://arxiv.org/abs/2405.10938
2.
Chen B, Cheng X, Li P, Geng Y, Gong J, Li S, et al. xTrimoPGLM: Unified 100B-Scale Pre-trained Transformer for Deciphering the Language of Protein. openRxiv; 2023. Available from: https://doi.org/10.1101/2023.07.05.547496