Summary
Fine-tuning PLMs ESM2, ProtT5, and Ankh virtually always improved property prediction (variant effect prediction, stability prediction, function prediction, others) compared to zero-shot (1). (2) found that active learning for directed evolution benefited from fine-tuning over zero-shot prediction after two to four rounds (fine-tuning carried out using a random forest model trained on mean-pooled embeddings).
Figures
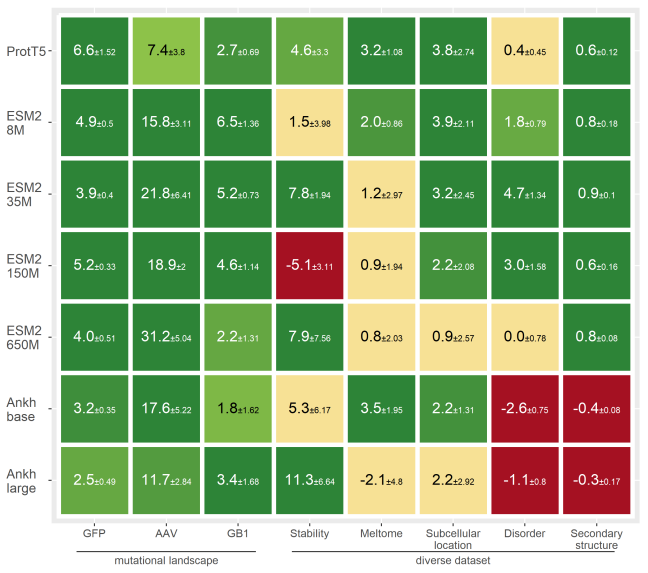
Figure 1 from (1)
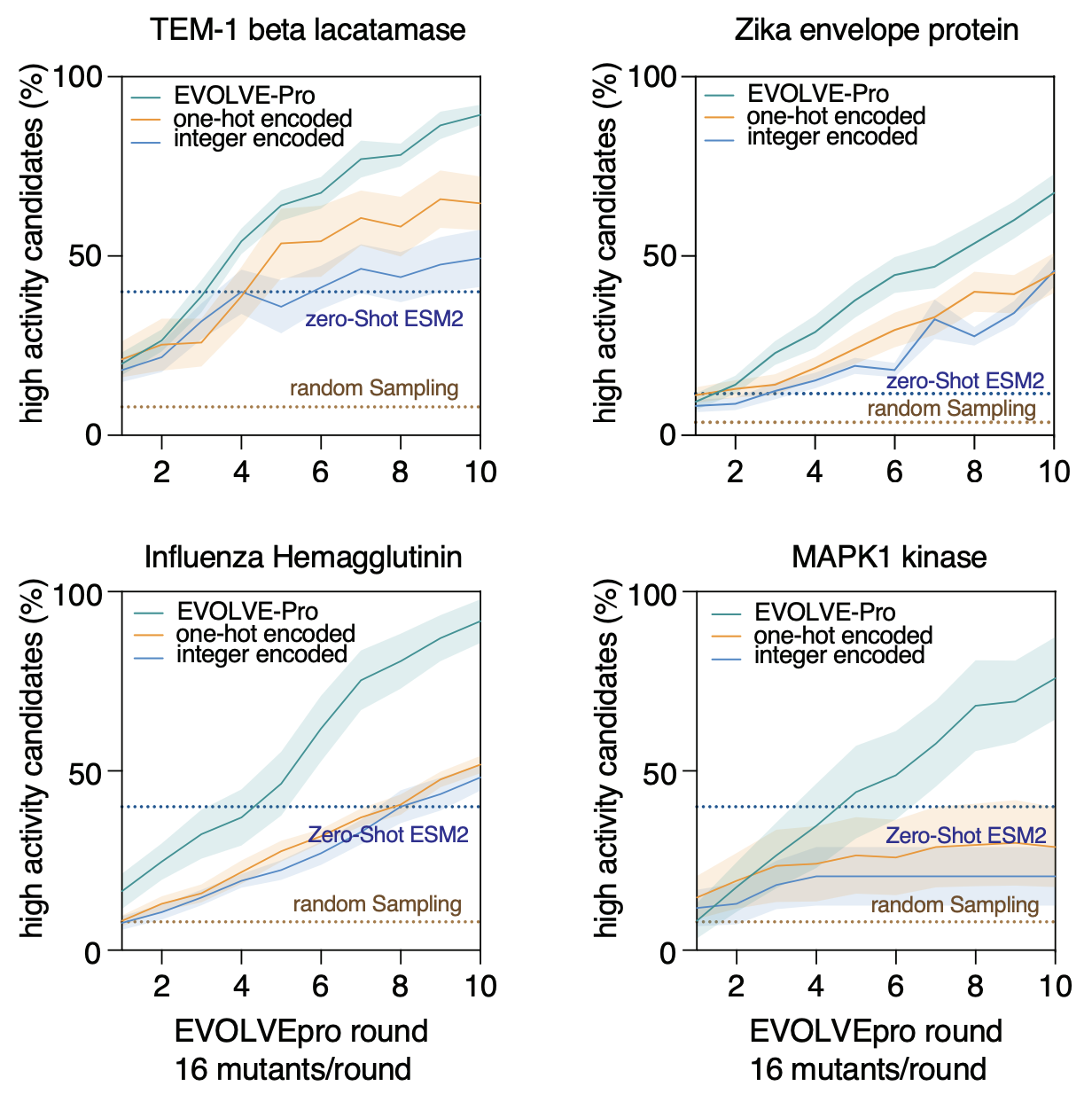
Ref (2)
See also
- Protein property prediction using PLMs does not benefit from scale except when predicting inferring features of either structural or sparsely populated sequence families
- Sequences with lower log-likelihoods are worse for zero-shot variant effect prediction using PLMs
1.
Schmirler R, Heinzinger M, Rost B. Fine-tuning protein language models boosts predictions across diverse tasks. Nature Communications. 2024;15(1). Available from: https://doi.org/10.1038/s41467-024-51844-2
2.
Jiang K, Yan Z, Bernardo MD, Sgrizzi SR, Villiger L, Kayabolen A, et al. Rapid protein evolution by few-shot learning with a protein language model. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.07.17.604015