Summary
Sequences with lower log-likelihood values yield poor zero-shot variant effect prediction values using protein language models (1,2). This can be mitigated by fine-tuning (1). In contrast, sequences with high log-likelihoods yield poorer predictions when using a fine-tuned model (i.e., the opposite result). However, this correlation breaks down as PLMs get larger.
Figures
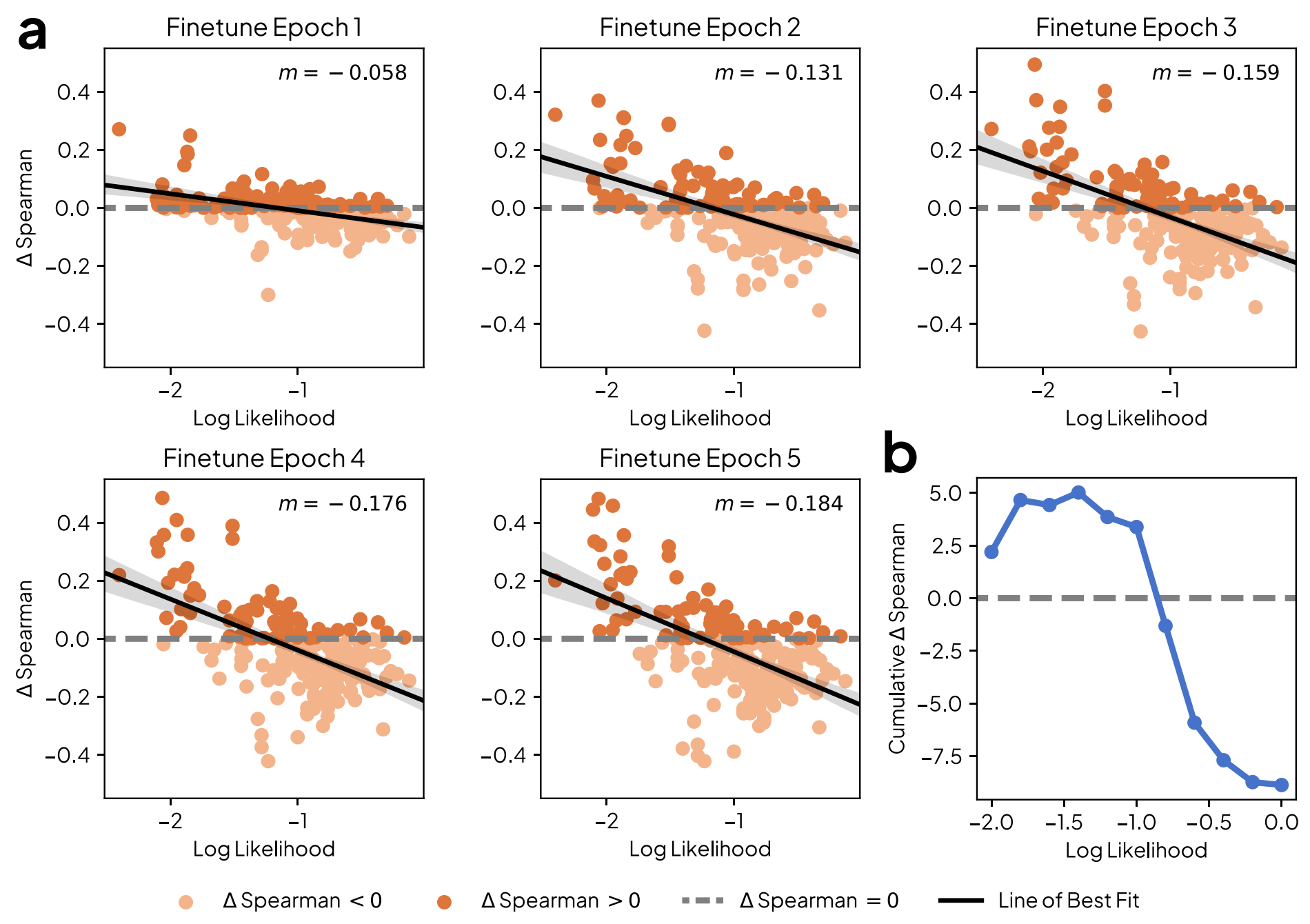 Figures from (1)
Figures from (1)
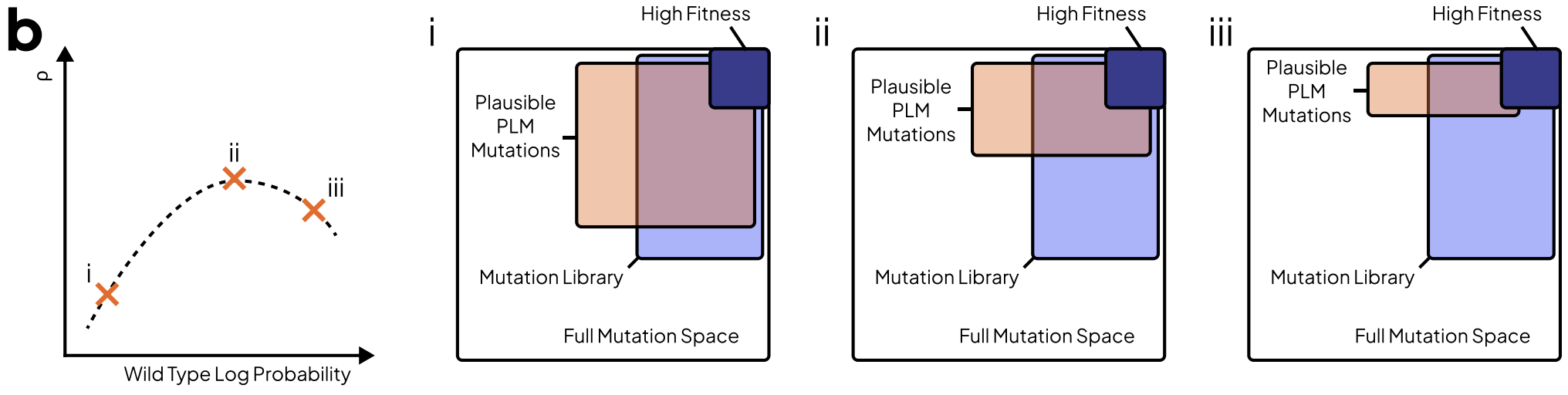
.png) Ref (2)
Ref (2)
See also
- PLMs are biased by uneven distribution of sequence data in datasets such as UniRef and UniProt
- PLMs downweigh probability of sequences with multiple mutations
1.
Gordon C, Lu AX, Abbeel P. Protein Language Model Fitness Is a Matter of Preference. openRxiv; 2024. Available from: https://doi.org/10.1101/2024.10.03.616542
2.
Wells J, Hooker AH, Livne M, Lin W, Miller D, Dallago C, et al. ProFam: Open-Source Protein Family Language Modelling for Fitness Prediction and Design. openRxiv; 2025. Available from: https://doi.org/10.64898/2025.12.19.695431