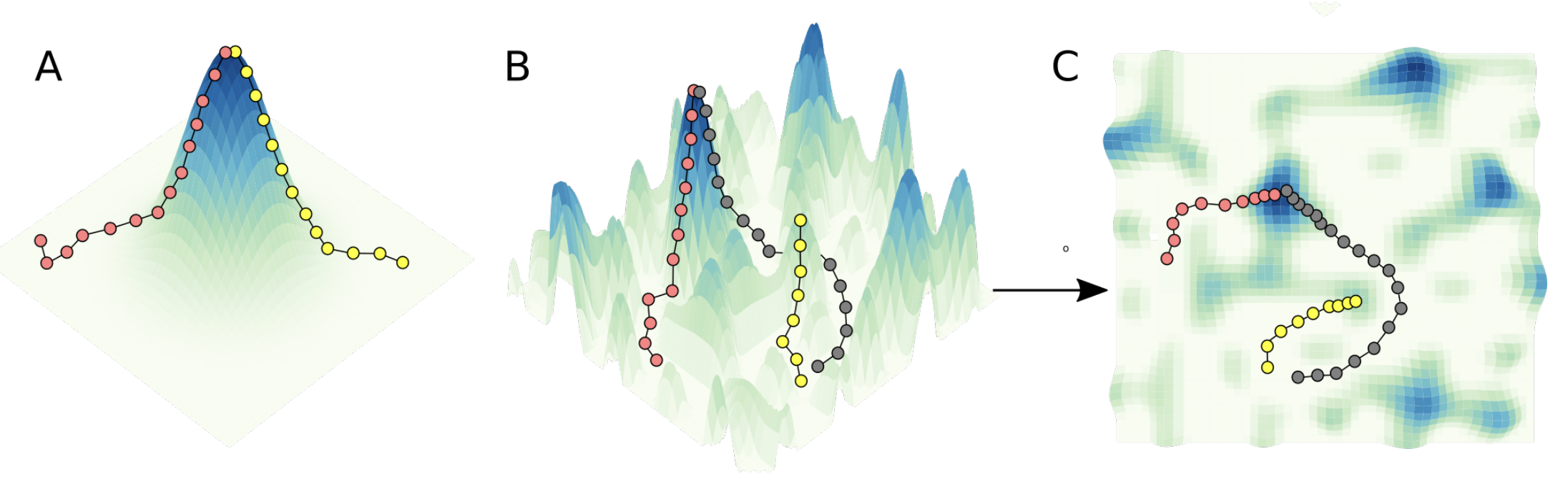
Fitness prediction describes the problem of predicting a protein’s fitness from its sequence, with or without structural data. It is affected by many other observables (stability, correct folding, etc) which can lead to epistasis, which is the inability to model fitness as a linear combination of the effects of individual mutations.
 Ref (1)
Ref (1)
Notes
- Sequence-based predictors (e.g., PSSMs and Potts models) could miss high-fitness naturally occurring mutations (2).
- Including nonfunctional sequences during training improves prediction of poor performers but not top performers (3). This was demonstrated using several ML models.
- Complex models are worse than ridge regression when the number of training examples is low (4).
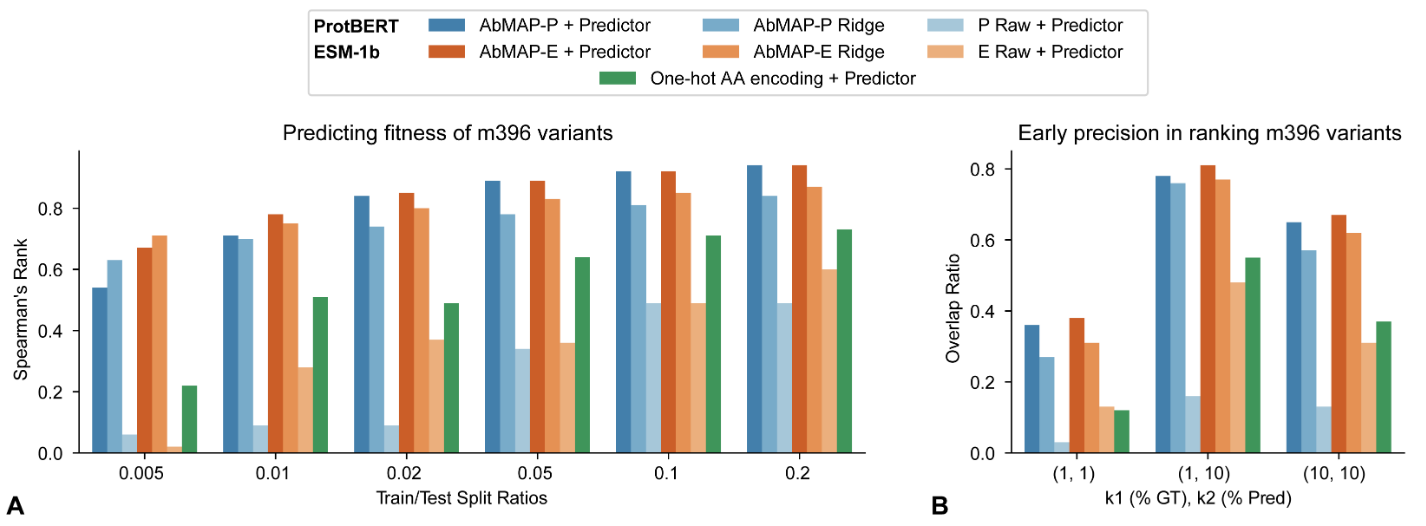 Ref (4)
Ref (4) - Threshold robustness refers to the fact that slightly deleterious mutations that negatively effect stability might have no impact on fitness up to a certain point, and that the effects can be devastating beyond this point.
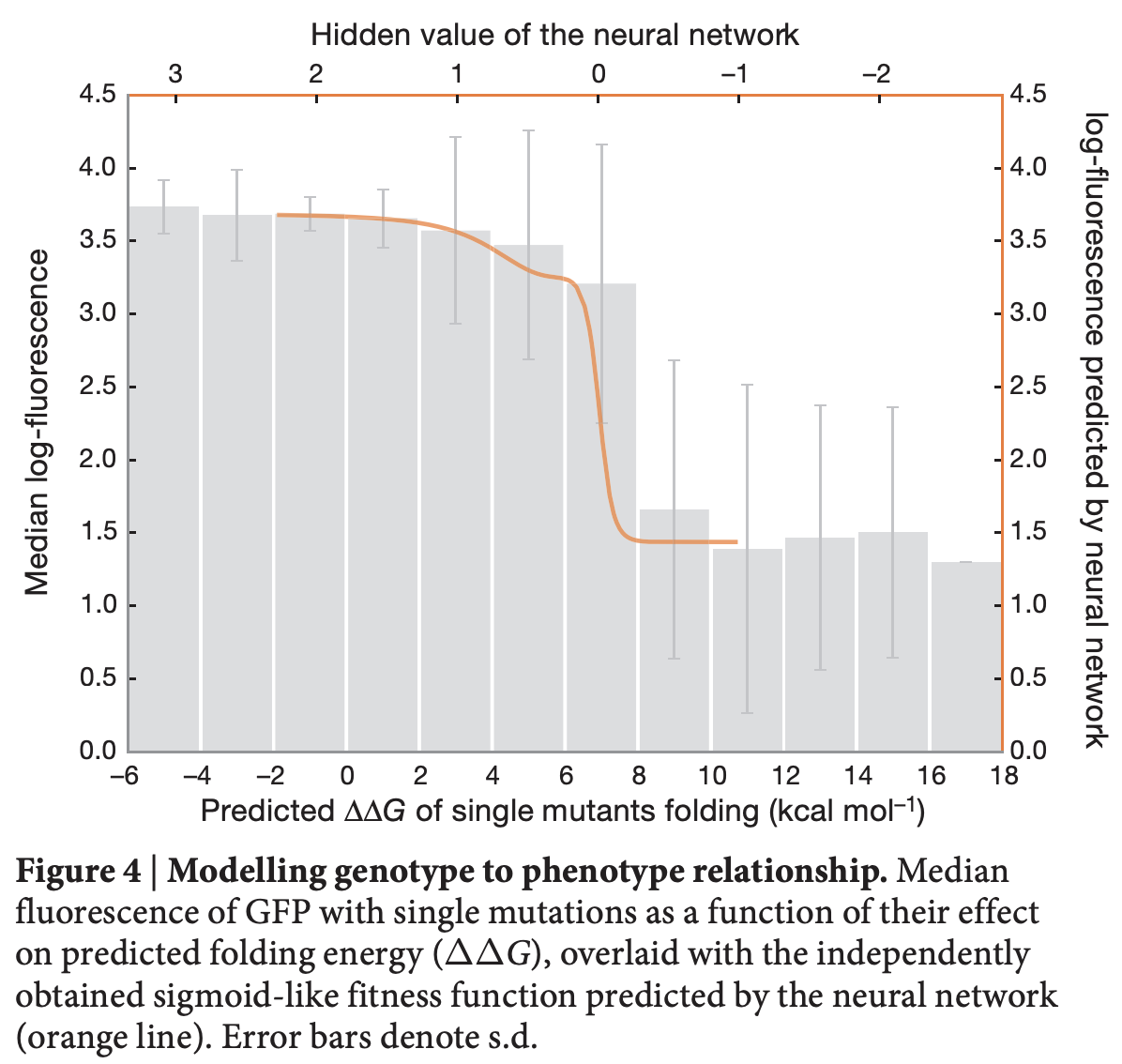 Ref (5)
Ref (5)
Evaluation
-
The Spearman correlation coefficient is the most widely used metric for evaluating how well methods can predict protein fitness.
-
Non-Discounted Cumulative Gains (NDCG) is used by other papers ((6,7), others), and measures how well predictions at the top end of a distribution are predicted. The cutoff is user-defined.
: Discount cumulative gain at rank . This penalizes the appearance of important results far from the top of the distribution : Ideal discount cumulative gain at rank ; basically the above but the rank-ordering is perfect. : Relevance score of result : Relevance score of result in its ideal position